Lecture 10: Resilient Distributed Datasets (RDDs) in Spark#
Learning Objectives#
By the end of this lecture, students should be able to:
Understand the concept of Resilient Distributed Datasets (RDDs) in Apache Spark.
Explain the immutability and fault tolerance features of RDDs.
Describe how RDDs enable parallel processing in a distributed computing environment.
Identify the key features of RDDs, including lazy evaluation and partitioning.
Introduction to RDDs#
Resilient Distributed Datasets (RDDs) are a foundational component in Apache Spark. They represent a distributed collection of data, partitioned across a cluster, which allows for parallel processing. RDDs are the core abstraction that enables Spark to handle large datasets efficiently across multiple machines.
Immutability: Once created, RDDs cannot be modified. Instead of changing an existing RDD, transformations (like map, filter, etc.) generate a new RDD from the original one. This immutability helps ensure consistency across distributed systems, as different machines or processes are always working with the same, unchangeable data.
Parallel processing: Since RDDs are distributed across multiple nodes, operations on them can be performed in parallel, leveraging the full power of a distributed computing environment. This makes it possible to process vast amounts of data much faster than on a single machine.
Fault tolerance: One of the key features of RDDs is their ability to recover from failures without the need to replicate the entire dataset. This is achieved through lineage, a concept where RDDs keep track of how they were derived from other RDDs. If a node or partition fails, Spark can use this lineage information to recompute only the affected parts of the dataset, minimizing data loss and avoiding the overhead of redundant copies.
Key Features of RDDs#
1. Immutability#
Once created, RDDs cannot be changed. Transformations on RDDs produce new RDDs.
What is immutable object?
In Python, immutability refers to objects whose state cannot be modified after they are created. For example, string, number, tuples are immutable objects in Python.
For example, when you try to overwrite the first letter of a string, it will give an error
string1 = 'Hello world'
string1[0] = 'A'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
File <command-1503943367388992>, line 2
1 string1 = 'Hello world'
----> 2 string1[0] = 'A'
TypeError: 'str' object does not support item assignment
Same for tuple. You cannot overwrite the object
tuple1 = (1, 2, 3)
tuple1[0] = 4
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
File <command-1503943367389002>, line 2
1 tuple1 = (1, 2, 3)
----> 2 tuple1[0] = 4
TypeError: 'tuple' object does not support item assignment
But with list you can, because list is mutable
list1 = [1, 2, 3]
list1[0] = 4
list1
[4, 2, 3]
Now come back to RDDs, what immutability means here is the fact that any transformation done on the data will create a new copy of the data, instead of overwriting it. This ensures that the original dataset remains unchanged, allowing for safer parallel processing and easier debugging.
2. Lazy Evaluation#
Transformations on RDDs are not executed immediately. They are computed only when an action is called. This means that Spark builds up a plan of transformations to apply when an action is finally invoked, optimizing the execution process and reducing unnecessary computations.
For example let’s take the following dataframe.
# Create a Spark DataFrame
data = [(1, 'Alice'), (2, 'Bob'), (3, 'Cathy')]
columns = ['id', 'name']
df = spark.createDataFrame(data, columns)
display(df)
| id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Cathy |
We want to filter the dataset based on id column. When you run the code cell below, actually nothing happen. PySpark will record the transformation but do not execute it yet. Think of it as PySpark writes down a recipe, but no food has been cooked yet
# Define a transformation (lazy evaluation)
filtered_df = df.filter(df['id'] > 1)
It will only execute the transformations when we trigger an action, such as display
# Action to trigger the evaluation
display(filtered_df)
| id | name |
|---|---|
| 2 | Bob |
| 3 | Cathy |
3. Fault Tolerance#
RDDs track lineage information to rebuild lost data. For example, if a partition of an RDD is lost due to a node failure, the RDD can use its lineage information to recompute the lost partition from the original data source or from other RDDs.
4. Partitioning#
RDDs are divided into partitions, which can be processed in parallel across the cluster.
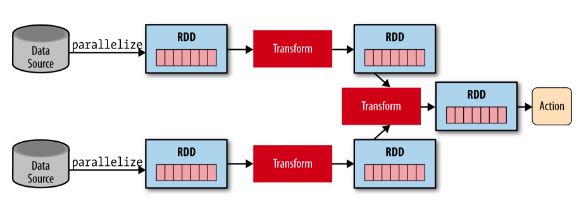
Transformations & Actions#
As we discussed above, RDDs is lazy-evaluated, which means it won’t execute the transformations until an action is triggered. Let’s have a closer look at this using some examples
Example: Creating RDDs from a csv File#
First, let’s try to read in a data file from an URL
# Import CSV from the given URL
url = "https://github.com/selva86/datasets/raw/master/AirPassengers.csv"
from pyspark import SparkFiles
# Add the file to the SparkContext
spark.sparkContext.addFile(url)
# Read the file
rdd = spark.sparkContext.textFile("file://"+SparkFiles.get("AirPassengers.csv"))
# Extract header
header = rdd.first()
# Remove header and split by commas
rdd = rdd.filter(lambda row: row != header).map(lambda row: row.split(","))
Can you guess where the data are being stored? They were actually partitioned and stored acrossed multiple servers. This is distributed computing! To see the number of partitions, we can run
rdd.getNumPartitions()
2
Let’s see what happens when we just try to display the dataframe by typing df. Typically, if this was a pandas.DataFrame, it woul display the first few rows.
However, since Spark is lazy-evaluated, it doesn’t display the data yet
rdd
PythonRDD[58] at RDD at PythonRDD.scala:61
To display the data, you need to trigger an action.
Now let’s trigger an action called collect(). The collect() function in PySpark is used to retrieve the entire dataset from the distributed environment (i.e., the cluster) back to the driver program as a list.
This method is often used for debugging or small datasets because it brings all the data into the driver’s memory, which can lead to memory issues if the dataset is large.
rdd.collect()
[['1949-01-01', '112'],
['1949-02-01', '118'],
['1949-03-01', '132'],
['1949-04-01', '129'],
['1949-05-01', '121'],
['1949-06-01', '135'],
['1949-07-01', '148'],
['1949-08-01', '148'],
['1949-09-01', '136'],
['1949-10-01', '119'],
['1949-11-01', '104'],
['1949-12-01', '118'],
['1950-01-01', '115'],
['1950-02-01', '126'],
['1950-03-01', '141'],
['1950-04-01', '135'],
['1950-05-01', '125'],
['1950-06-01', '149'],
['1950-07-01', '170'],
['1950-08-01', '170'],
['1950-09-01', '158'],
['1950-10-01', '133'],
['1950-11-01', '114'],
['1950-12-01', '140'],
['1951-01-01', '145'],
['1951-02-01', '150'],
['1951-03-01', '178'],
['1951-04-01', '163'],
['1951-05-01', '172'],
['1951-06-01', '178'],
['1951-07-01', '199'],
['1951-08-01', '199'],
['1951-09-01', '184'],
['1951-10-01', '162'],
['1951-11-01', '146'],
['1951-12-01', '166'],
['1952-01-01', '171'],
['1952-02-01', '180'],
['1952-03-01', '193'],
['1952-04-01', '181'],
['1952-05-01', '183'],
['1952-06-01', '218'],
['1952-07-01', '230'],
['1952-08-01', '242'],
['1952-09-01', '209'],
['1952-10-01', '191'],
['1952-11-01', '172'],
['1952-12-01', '194'],
['1953-01-01', '196'],
['1953-02-01', '196'],
['1953-03-01', '236'],
['1953-04-01', '235'],
['1953-05-01', '229'],
['1953-06-01', '243'],
['1953-07-01', '264'],
['1953-08-01', '272'],
['1953-09-01', '237'],
['1953-10-01', '211'],
['1953-11-01', '180'],
['1953-12-01', '201'],
['1954-01-01', '204'],
['1954-02-01', '188'],
['1954-03-01', '235'],
['1954-04-01', '227'],
['1954-05-01', '234'],
['1954-06-01', '264'],
['1954-07-01', '302'],
['1954-08-01', '293'],
['1954-09-01', '259'],
['1954-10-01', '229'],
['1954-11-01', '203'],
['1954-12-01', '229'],
['1955-01-01', '242'],
['1955-02-01', '233'],
['1955-03-01', '267'],
['1955-04-01', '269'],
['1955-05-01', '270'],
['1955-06-01', '315'],
['1955-07-01', '364'],
['1955-08-01', '347'],
['1955-09-01', '312'],
['1955-10-01', '274'],
['1955-11-01', '237'],
['1955-12-01', '278'],
['1956-01-01', '284'],
['1956-02-01', '277'],
['1956-03-01', '317'],
['1956-04-01', '313'],
['1956-05-01', '318'],
['1956-06-01', '374'],
['1956-07-01', '413'],
['1956-08-01', '405'],
['1956-09-01', '355'],
['1956-10-01', '306'],
['1956-11-01', '271'],
['1956-12-01', '306'],
['1957-01-01', '315'],
['1957-02-01', '301'],
['1957-03-01', '356'],
['1957-04-01', '348'],
['1957-05-01', '355'],
['1957-06-01', '422'],
['1957-07-01', '465'],
['1957-08-01', '467'],
['1957-09-01', '404'],
['1957-10-01', '347'],
['1957-11-01', '305'],
['1957-12-01', '336'],
['1958-01-01', '340'],
['1958-02-01', '318'],
['1958-03-01', '362'],
['1958-04-01', '348'],
['1958-05-01', '363'],
['1958-06-01', '435'],
['1958-07-01', '491'],
['1958-08-01', '505'],
['1958-09-01', '404'],
['1958-10-01', '359'],
['1958-11-01', '310'],
['1958-12-01', '337'],
['1959-01-01', '360'],
['1959-02-01', '342'],
['1959-03-01', '406'],
['1959-04-01', '396'],
['1959-05-01', '420'],
['1959-06-01', '472'],
['1959-07-01', '548'],
['1959-08-01', '559'],
['1959-09-01', '463'],
['1959-10-01', '407'],
['1959-11-01', '362'],
['1959-12-01', '405'],
['1960-01-01', '417'],
['1960-02-01', '391'],
['1960-03-01', '419'],
['1960-04-01', '461'],
['1960-05-01', '472'],
['1960-06-01', '535'],
['1960-07-01', '622'],
['1960-08-01', '606'],
['1960-09-01', '508'],
['1960-10-01', '461'],
['1960-11-01', '390'],
['1960-12-01', '432']]
The take() function in PySpark is used to retrieve a specified number of elements from an RDD or DataFrame. It returns the first n elements as a list, where n is the number you specify.
rdd.take(10)
[['1949-01-01', '112'],
['1949-02-01', '118'],
['1949-03-01', '132'],
['1949-04-01', '129'],
['1949-05-01', '121'],
['1949-06-01', '135'],
['1949-07-01', '148'],
['1949-08-01', '148'],
['1949-09-01', '136'],
['1949-10-01', '119']]
RDD Transformations#
Transformations are operations on RDDs that return a new RDD.
Examples include
map(),filter(),flatMap(),reduceByKey(), andjoin().
Example: Using map() and filter()#
# Create an RDD from a list
rdd = sc.parallelize(range(1, 101))
# Use map to square each element
squared_rdd = rdd.map(lambda x: x ** 2)
# Apply a filter transformation to keep only even numbers
even_rdd = squared_rdd.filter(lambda x: x % 2 == 0)
squared_rdd
PythonRDD[67] at RDD at PythonRDD.scala:61
Notice that when we try to print out squared_rdd, nothing happens, because we have not trigger an action
# Collect and print the results
print(even_rdd.collect())
[4, 16, 36, 64, 100, 144, 196, 256, 324, 400, 484, 576, 676, 784, 900, 1024, 1156, 1296, 1444, 1600, 1764, 1936, 2116, 2304, 2500, 2704, 2916, 3136, 3364, 3600, 3844, 4096, 4356, 4624, 4900, 5184, 5476, 5776, 6084, 6400, 6724, 7056, 7396, 7744, 8100, 8464, 8836, 9216, 9604, 10000]
A better way would be using the take() function, since it won’t bring the whole dataset into memory
even_rdd.take(3)
[4, 16, 36]
Example of join#
# Create two RDDs with key-value pairs
rdd1 = sc.parallelize([(1, "apple"), (2, "banana"), (3, "cherry")])
rdd2 = sc.parallelize([(1, "red"), (2, "yellow"), (3, "red"), (4, "green")])
# Perform a join operation on the two RDDs
joined_rdd = rdd1.join(rdd2)
# Collect and print the results
print(joined_rdd.collect())
[(1, ('apple', 'red')), (2, ('banana', 'yellow')), (3, ('cherry', 'red'))]
RDD Actions#
Actions are operations that trigger the execution of transformations and return a result.
Examples include
collect(),count(),take(), andreduce().
Example: Using reduce()#
The reduce() function in PySpark is an action that aggregates the elements of an RDD using a specified binary operator. It takes a function that operates on two elements of the RDD and returns a single element.
# Use reduce to sum all elements
sum_result = rdd.reduce(lambda x, y: x + y)
# Print the result
print(sum_result)
5050
5 Reasons on When to use RDDs#
You want low-level transformation and actions and control on your dataset;
Your data is unstructured, such as media streams or streams of text;
You want to manipulate your data with functional programming constructs than domain specific expressions;
You don’t care about imposing a schema, such as columnar format while processing or accessing data attributes by name or column; and
You can forgo some optimization and performance benefits available with DataFrames and Datasets for structured and semi-structured data.
References