Worksheet 3: CRUD operations in MongoDB#
Welcome! In this week, we will practice some basic CRUD (Create, Replace, Update, Delete) operations in MongoDB using Pymongo.
Establish Pymongo connection#
Recall that in worksheet1, we have created a cluster on MongoDB Atlas and connect to it via Pymongo and a credentials JSON file. Let’s reestablish that connection for our exercises.
Make sure you use the
adsc_3610conda environment.You might need to copy & paste the
credentials_mongodb.jsonfile that you used in worksheet1 to the working directory of worksheet3.
from pymongo import MongoClient # import mongo client to connect
import json # import json to load credentials
import urllib.parse
# load credentials from json file
with open('credentials_mongodb.json') as f:
login = json.load(f)
# assign credentials to variables
username = login['username']
password = urllib.parse.quote(login['password'])
host = login['host']
url = "mongodb+srv://{}:{}@{}/?retryWrites=true&w=majority".format(username, password, host)
# connect to the database
client = MongoClient(url)
# drop database books and students if they exist
client.drop_database('bookstore')
client.drop_database('students')
To test if your connection has been succesful, let’s try to print out all the databases
# list all databases
client.list_database_names()
['library',
'sample_airbnb',
'sample_analytics',
'sample_geospatial',
'sample_guides',
'sample_mflix',
'sample_restaurants',
'sample_supplies',
'sample_training',
'sample_weatherdata',
'school',
'admin',
'local']
MongoDB VScode extension (optional)#
If you are using VScode, there is a MongoDB extension which provides a handy view of the databases (instead of having to view it on MongoDB Atlas via a browser).
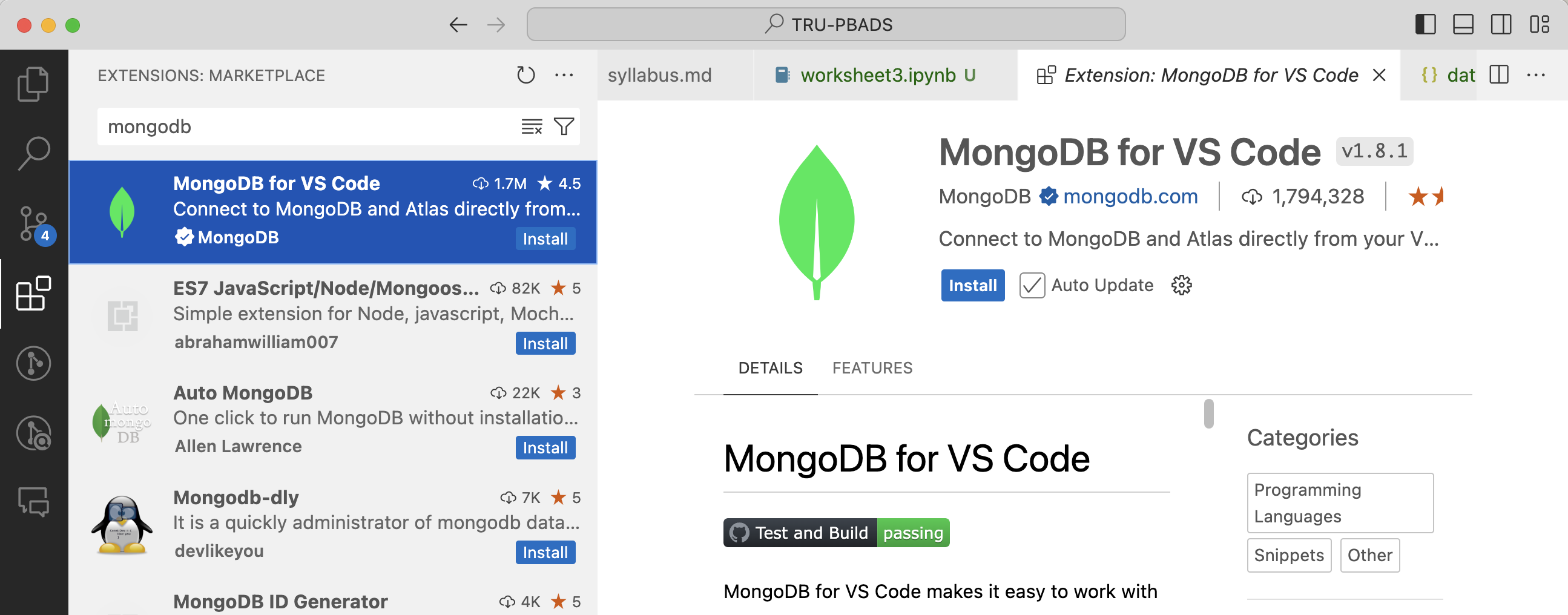
To install the extension, navigate to the extension bar in VS code and search for “mongodb”
After installing the extension, you can now connect to your MongoDB Atlas cluster via the connection string.
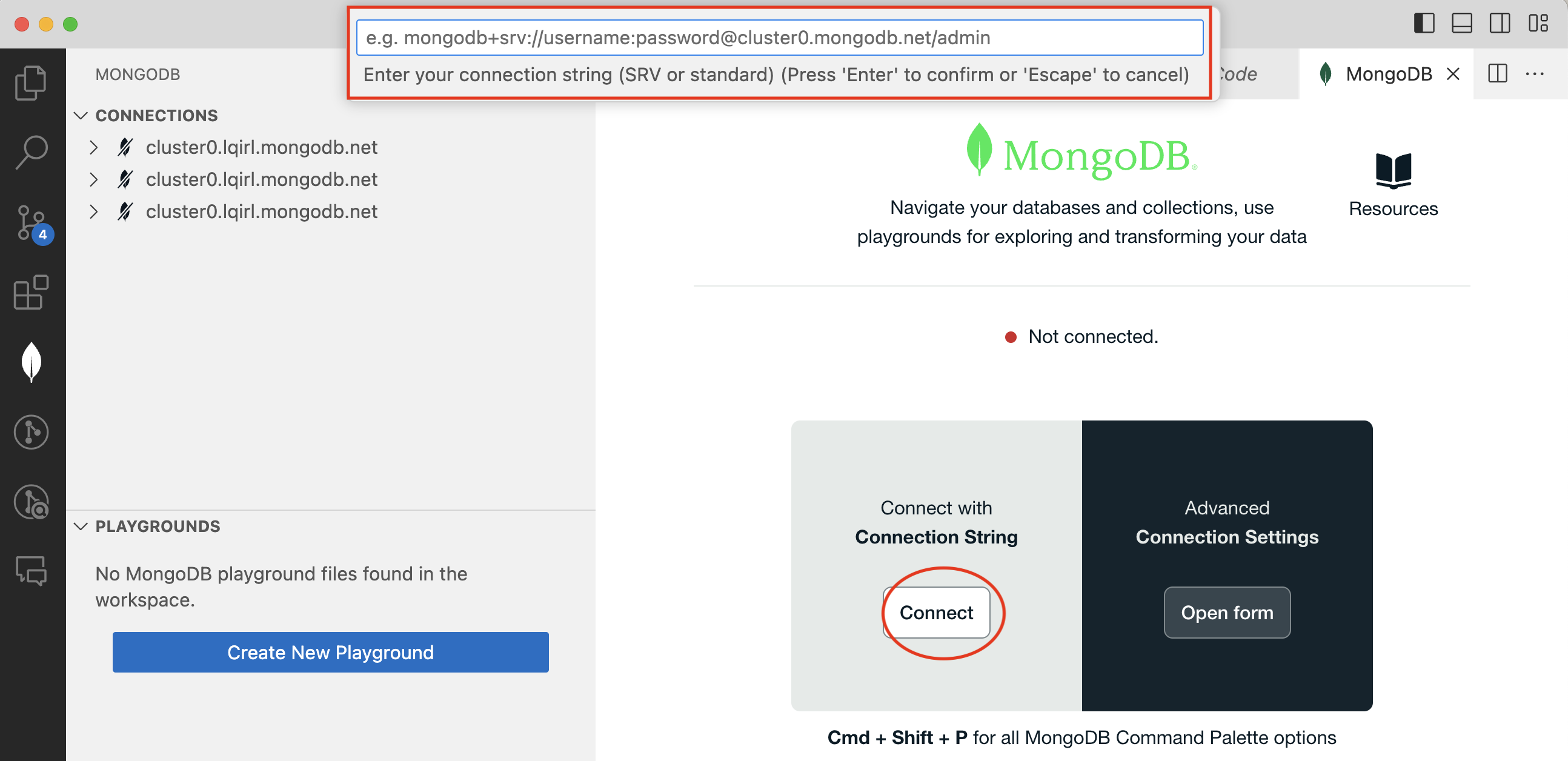
To find your connection string, open a browser and navigate to MongoDB Atlas.
Under your cluster, click
connectSelect
MongoDB for VScodeCopy that URL and paste it in VScode
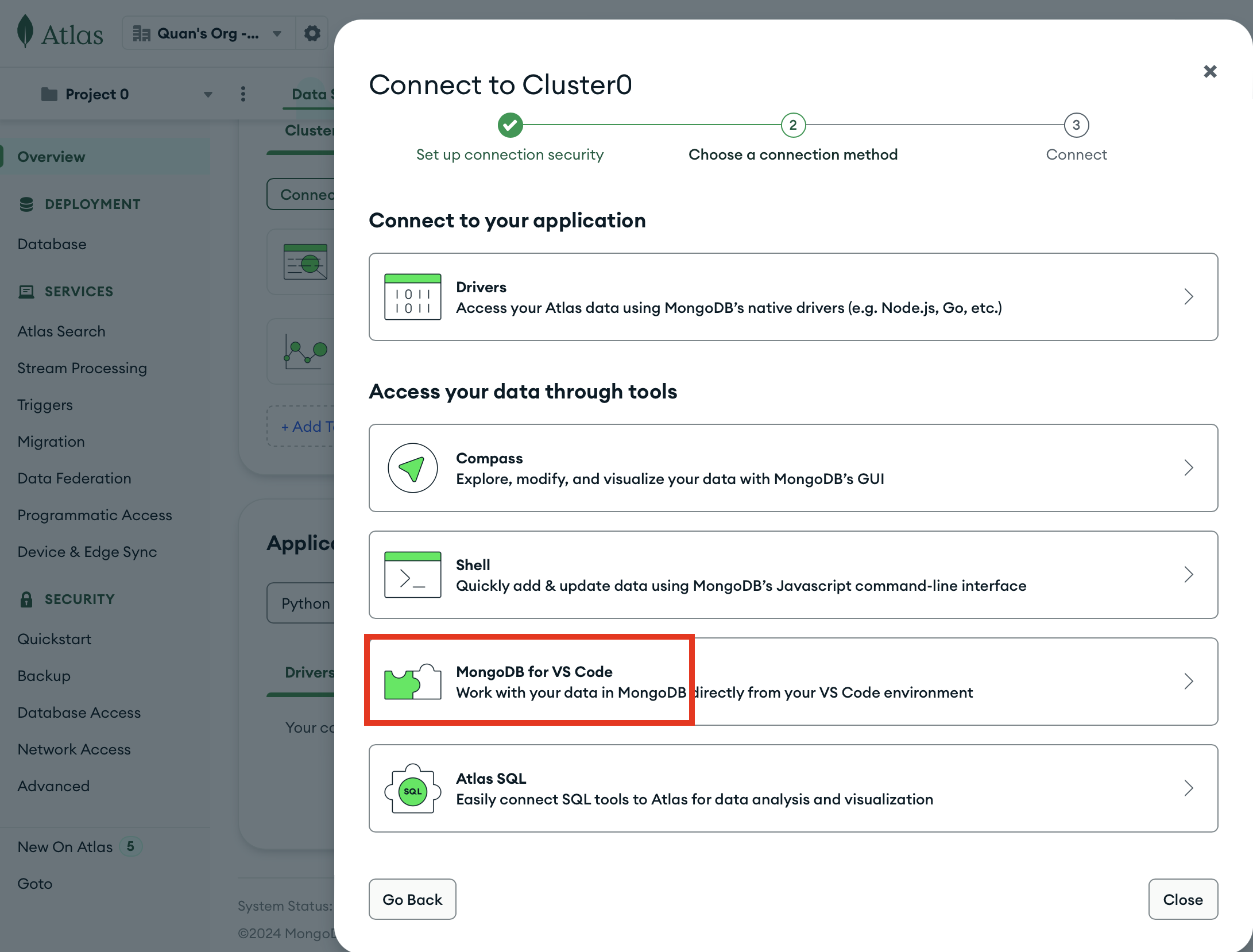
Once connected, you should now be able to see an overview of your databases. Now you can manage your MongoDB and do programming all within VSCode.
Now that we have establish the connection to our MongoDB cluster, let’s get started with the exercises:
Exercise 1: Import data into MongoDB#
{rubric: accuracy = 5}
Let’s first create a new database called school and store it in an object named db. We then create a new collection called students
# Step 1: Connect to your MongoDB cluster
client = MongoClient(url)
# Step 2: Create a new database named 'school' and store it in a variable named db
db = client.school
# Step 3: Create a collection named 'students' and insert sample documents
students = db.students
Let’s insert a sample student document to our students collection
# Sample document to insert
sample_students = [{"name": "Alice", "age": 20, "major": "Computer Science"},
{"name": "Bob", "age": 21, "major": "Mathematics"},
{"name": "Charlie", "age": 22, "major": "Engineering"}]
# Insert the sample document
students.insert_many(sample_students)
InsertManyResult([ObjectId('66f1c50f2a1f550705a4f5d3'), ObjectId('66f1c50f2a1f550705a4f5d4'), ObjectId('66f1c50f2a1f550705a4f5d5')], acknowledged=True)
You should see that the document has been inserted into our students collection, and it was assigned an ObjectId.
Note: Every document in MongoDB must have an
ObjectId. If it doesn’t exist, then MongoDB will create a new one automatically
Now we can print out the documents that we just inserted
# Find the document that was just inserted
# The find_one() method returns the first occurrence in the selection.
students.find_one()
{'_id': ObjectId('66e8885dc48457d8d5b1262c'),
'name': 'Alice',
'age': 20,
'major': 'Computer Science',
'gpa': None}
# Find the document by a specific attribute
students.find_one({"name": "Bob"})
{'_id': ObjectId('66e8885dc48457d8d5b1262d'),
'name': 'Bob',
'age': 21,
'major': 'Mathematics',
'gpa': None}
# Find all documents in the collection
# The find() method returns all occurrences in the selection.
for student in students.find():
print(student)
{'_id': ObjectId('66e8885dc48457d8d5b1262c'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66e8885dc48457d8d5b1262d'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12631'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12632'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12636'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66e8970fc48457d8d5b12655'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66e8970fc48457d8d5b12656'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b1265d'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b1265e'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b12662'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4df2a1f550705a4f5b7'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66f1c4df2a1f550705a4f5b8'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5bf'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5c0'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5c4'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d3'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science'}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d4'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics'}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d5'), 'name': 'Charlie', 'age': 22, 'major': 'Engineering'}
Now if you navigate to your databases in MongoDB Atlas, or using the VSCode MongoDB extension, you should see there’s a new database called school. Within that database, there should be a collection named students, which contains one document about Alice
# Try to find all documents where age is greater than 20
for student in students.find({"age": {"$gt": 20}}):
print(student)
{'_id': ObjectId('66e8885dc48457d8d5b1262d'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12632'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12636'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66e8970fc48457d8d5b12656'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b1265e'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b12662'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4df2a1f550705a4f5b8'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5c0'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5c4'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d4'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics'}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d5'), 'name': 'Charlie', 'age': 22, 'major': 'Engineering'}
YOUR TURN#
1.1#
Create a new database called
bookstore, stored it in a variable calledbookstoreCreate a collection called
books, stored it in a variable calledbooks
# Create a new database called `bookstore`, stored it in a variable called `bookstore`
# YOUR CODE HERE
bookstore = client.bookstore # SOLUTION
# Create a collection called `books`
# YOUR CODE HERE
books = bookstore.books # SOLUTION
Insert the following sample documents in sample_books into the books collection
sample_books = [
{"title": "The Great Gatsby", "author": "F. Scott Fitzgerald", "genre": "Fiction", "price": 10.99},
{"title": "To Kill a Mockingbird", "author": "Harper Lee", "genre": "Fiction", "price": 8.99},
{"title": "A Brief History of Time", "author": "Stephen Hawking", "genre": "Non-Fiction", "price": 15.99}
]
# YOUR CODE HERE
# BEGIN SOLUTION
# Insert the sample_books into the books collection
books.insert_many(sample_books)
# END SOLUTION
InsertManyResult([ObjectId('66f1c50f2a1f550705a4f5d6'), ObjectId('66f1c50f2a1f550705a4f5d7'), ObjectId('66f1c50f2a1f550705a4f5d8')], acknowledged=True)
Print out a book with author as Stephen Hawking
# Print out a book with author as Stephen Hawking
# YOUR CODE HERE
books.find_one({"author": "Stephen Hawking"}) # SOLUTION
{'_id': ObjectId('66f1c50f2a1f550705a4f5d8'),
'title': 'A Brief History of Time',
'author': 'Stephen Hawking',
'genre': 'Non-Fiction',
'price': 15.99}
# Print out all books with price less than $10
# YOUR CODE HERE
for book in books.find({"price": {"$lt": 10}}): # SOLUTION
print(book) # SOLUTION
{'_id': ObjectId('66f1c50f2a1f550705a4f5d7'), 'title': 'To Kill a Mockingbird', 'author': 'Harper Lee', 'genre': 'Fiction', 'price': 8.99}
Run the test below to see if you have done it correctly
# assert bookstore and books exist
assert 'bookstore' in client.list_database_names(), "bookstore database does not exist"
assert 'books' in bookstore.list_collection_names(), "books collection does not exist"
# assert sample_books were inserted
assert books.find_one({"author": "Stephen Hawking"}) is not None, "sample_books were not inserted"
# assert "title": "To Kill a Mockingbird" is in the collection
assert books.find_one({"title": "To Kill a Mockingbird"}) is not None, "To Kill a Mockingbird is not in the collection"
1.2 Import from JSON#
Imagine we have a dataset called students.json and we would like to import it into the students collection in our MongoDB database.
import json
# Step 1: Load JSON data
with open('students.json', 'r') as file:
data = json.load(file)
# view what the data looks like (first 5 records)
data[:5]
[{'name': 'Alice Johnson',
'age': 22,
'major': 'Computer Science',
'email': 'alice.johnson@example.com'},
{'name': 'Bob Smith',
'age': 24,
'major': 'Mathematics',
'email': 'bob.smith@example.com'},
{'name': 'Charlie Brown',
'age': 20,
'major': 'Physics',
'email': 'charlie.brown@example.com'},
{'name': 'Diana Prince',
'age': 21,
'major': 'History',
'email': 'diana.prince@example.com'},
{'name': 'Eve Adams',
'age': 23,
'major': 'Biology',
'email': 'eve.adams@example.com'}]
# Step 2: Insert JSON data into a collection
students.insert_many(data) # For a list of documents
InsertManyResult([ObjectId('66f1c5102a1f550705a4f5d9'), ObjectId('66f1c5102a1f550705a4f5da'), ObjectId('66f1c5102a1f550705a4f5db'), ObjectId('66f1c5102a1f550705a4f5dc'), ObjectId('66f1c5102a1f550705a4f5dd'), ObjectId('66f1c5102a1f550705a4f5de'), ObjectId('66f1c5102a1f550705a4f5df'), ObjectId('66f1c5102a1f550705a4f5e0'), ObjectId('66f1c5102a1f550705a4f5e1'), ObjectId('66f1c5102a1f550705a4f5e2')], acknowledged=True)
# Find all documents in the collection
# The find() method returns all occurrences in the selection.
for student in students.find():
print(student)
{'_id': ObjectId('66e8885dc48457d8d5b1262c'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66e8885dc48457d8d5b1262d'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12631'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12632'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12636'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66e8970fc48457d8d5b12655'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66e8970fc48457d8d5b12656'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b1265d'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b1265e'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b12662'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4df2a1f550705a4f5b7'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66f1c4df2a1f550705a4f5b8'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5bf'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5c0'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5c4'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d3'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science'}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d4'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics'}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d5'), 'name': 'Charlie', 'age': 22, 'major': 'Engineering'}
{'_id': ObjectId('66f1c5102a1f550705a4f5d9'), 'name': 'Alice Johnson', 'age': 22, 'major': 'Computer Science', 'email': 'alice.johnson@example.com'}
{'_id': ObjectId('66f1c5102a1f550705a4f5da'), 'name': 'Bob Smith', 'age': 24, 'major': 'Mathematics', 'email': 'bob.smith@example.com'}
{'_id': ObjectId('66f1c5102a1f550705a4f5db'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com'}
{'_id': ObjectId('66f1c5102a1f550705a4f5dc'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com'}
{'_id': ObjectId('66f1c5102a1f550705a4f5dd'), 'name': 'Eve Adams', 'age': 23, 'major': 'Biology', 'email': 'eve.adams@example.com'}
{'_id': ObjectId('66f1c5102a1f550705a4f5de'), 'name': 'Frank Wright', 'age': 22, 'major': 'Chemistry', 'email': 'frank.wright@example.com'}
{'_id': ObjectId('66f1c5102a1f550705a4f5df'), 'name': 'Grace Hopper', 'age': 24, 'major': 'Computer Engineering', 'email': 'grace.hopper@example.com'}
{'_id': ObjectId('66f1c5102a1f550705a4f5e0'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com'}
{'_id': ObjectId('66f1c5102a1f550705a4f5e1'), 'name': 'Ivy League', 'age': 23, 'major': 'Literature', 'email': 'ivy.league@example.com'}
{'_id': ObjectId('66f1c5102a1f550705a4f5e2'), 'name': 'Jack Daniels', 'age': 22, 'major': 'Business', 'email': 'jack.daniels@example.com'}
Now it’s your turn, import the books.json into the books collection in the bookstore database in your MongoDB.
# BEGIN SOLUTION
with open('books.json', 'r') as file:
data = json.load(file)
books.insert_many(data) # For a list of documents
# END SOLUTION
InsertManyResult([ObjectId('66f1c5102a1f550705a4f5e3'), ObjectId('66f1c5102a1f550705a4f5e4'), ObjectId('66f1c5102a1f550705a4f5e5'), ObjectId('66f1c5102a1f550705a4f5e6'), ObjectId('66f1c5102a1f550705a4f5e7'), ObjectId('66f1c5102a1f550705a4f5e8'), ObjectId('66f1c5102a1f550705a4f5e9'), ObjectId('66f1c5102a1f550705a4f5ea'), ObjectId('66f1c5102a1f550705a4f5eb'), ObjectId('66f1c5102a1f550705a4f5ec')], acknowledged=True)
assert books.find_one({"title": "Pride and Prejudice"}) is not None, "Pride and Prejudice is not in the collection"
assert books.find_one({"isbn": "978-0-06-112008-4"}) is not None, "ISBN 978-0-06-112008-4 is not in the collection"
Exercise 2: Insert & update new field#
Let’s say we want to add a field called gpa to the students collection. Here’s how
# Step 1: Define the new field and its value
new_field = {"gpa": None}
# Step 2: Update all documents to include the new field
students.update_many({}, {"$set": new_field})
UpdateResult({'n': 28, 'electionId': ObjectId('7fffffff00000000000000cb'), 'opTime': {'ts': Timestamp(1727120656, 42), 't': 203}, 'nModified': 13, 'ok': 1.0, '$clusterTime': {'clusterTime': Timestamp(1727120656, 42), 'signature': {'hash': b'=\x98\x93T\x06\xbf\xb3|6^H\xbf\x1c\xf6\x97w\x0c\x17k\xa8', 'keyId': 7381891571605569538}}, 'operationTime': Timestamp(1727120656, 42), 'updatedExisting': True}, acknowledged=True)
# check if the new field was added
for student in students.find():
print(student)
{'_id': ObjectId('66e8885dc48457d8d5b1262c'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66e8885dc48457d8d5b1262d'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12631'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12632'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12636'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66e8970fc48457d8d5b12655'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66e8970fc48457d8d5b12656'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b1265d'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b1265e'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b12662'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4df2a1f550705a4f5b7'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66f1c4df2a1f550705a4f5b8'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5bf'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5c0'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5c4'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d3'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d4'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d5'), 'name': 'Charlie', 'age': 22, 'major': 'Engineering', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5d9'), 'name': 'Alice Johnson', 'age': 22, 'major': 'Computer Science', 'email': 'alice.johnson@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5da'), 'name': 'Bob Smith', 'age': 24, 'major': 'Mathematics', 'email': 'bob.smith@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5db'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5dc'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5dd'), 'name': 'Eve Adams', 'age': 23, 'major': 'Biology', 'email': 'eve.adams@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5de'), 'name': 'Frank Wright', 'age': 22, 'major': 'Chemistry', 'email': 'frank.wright@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5df'), 'name': 'Grace Hopper', 'age': 24, 'major': 'Computer Engineering', 'email': 'grace.hopper@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5e0'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5e1'), 'name': 'Ivy League', 'age': 23, 'major': 'Literature', 'email': 'ivy.league@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5e2'), 'name': 'Jack Daniels', 'age': 22, 'major': 'Business', 'email': 'jack.daniels@example.com', 'gpa': None}
Let’s try to update the gpa of Jack Daniels to 3.4
# Step 2: Define the filter and the new value
filter = {"name": "Jack Daniels"}
new_value = {"$set": {"gpa": 3.4}}
# Step 3: Update the specific document
students.update_one(filter, new_value)
UpdateResult({'n': 1, 'electionId': ObjectId('7fffffff00000000000000cb'), 'opTime': {'ts': Timestamp(1727120656, 44), 't': 203}, 'nModified': 1, 'ok': 1.0, '$clusterTime': {'clusterTime': Timestamp(1727120656, 44), 'signature': {'hash': b'=\x98\x93T\x06\xbf\xb3|6^H\xbf\x1c\xf6\x97w\x0c\x17k\xa8', 'keyId': 7381891571605569538}}, 'operationTime': Timestamp(1727120656, 44), 'updatedExisting': True}, acknowledged=True)
# check Jack Daniels GPA
students.find_one({"name": "Jack Daniels"})
{'_id': ObjectId('66f1c5102a1f550705a4f5e2'),
'name': 'Jack Daniels',
'age': 22,
'major': 'Business',
'email': 'jack.daniels@example.com',
'gpa': 3.4}
Now it’s your turn.
Insert a field called
"publisher"into thebookscollection with a default value of"Unknown".Update the
publisherof the book with the author name is “Ray Bradbury”, to “Penguin Books”
# BEGIN SOLUTION
books.update_many({}, {"$set": {"publisher": "Unknown"}})
books.update_one({"author": "Ray Bradbury"}, {"$set": {"publisher": "Penguin Books"}})
# END SOLUTION
UpdateResult({'n': 1, 'electionId': ObjectId('7fffffff00000000000000cb'), 'opTime': {'ts': Timestamp(1727120656, 58), 't': 203}, 'nModified': 1, 'ok': 1.0, '$clusterTime': {'clusterTime': Timestamp(1727120656, 58), 'signature': {'hash': b'=\x98\x93T\x06\xbf\xb3|6^H\xbf\x1c\xf6\x97w\x0c\x17k\xa8', 'keyId': 7381891571605569538}}, 'operationTime': Timestamp(1727120656, 58), 'updatedExisting': True}, acknowledged=True)
# print out the document by Ray Bradbury
# check if the publisher field was added
assert books.find_one({"author": "Ray Bradbury"})["publisher"] == "Penguin Books", "publisher field was not added"
Exercise 3: Replace#
Let’s print out our student Jack Daniels
students.find_one({"name": "Jack Daniels"})
{'_id': ObjectId('66f1c5102a1f550705a4f5e2'),
'name': 'Jack Daniels',
'age': 22,
'major': 'Business',
'email': 'jack.daniels@example.com',
'gpa': 3.4}
Let’s say we want to replace the entire document by a new one. Let’s called this new_student
new_student = {
"name": "John Doe",
"age": 25,
"major": "History",
"email": "john_doe@gmail.com",
"gpa": 3.1
}
students.replace_one({"name": "Jack Daniels"}, new_student)
# check if Jack Daniels was replaced
students.find_one({"name": "Jack Daniels"})
students.find_one({"name": "John Doe"})
{'_id': ObjectId('66f1c5102a1f550705a4f5e2'),
'name': 'John Doe',
'age': 25,
'major': 'History',
'email': 'john_doe@gmail.com',
'gpa': 3.1}
Now it’s your turn.
Replace the book by Stephen Hawking with the new_book
new_book = {
"title": "The Universe in a Nutshell",
"author": "Stephen Hawking",
"genre": "Non-Fiction",
"price": 12.99,
"publisher": "Bantam Books"
}
# YOUR CODE HERE
books.replace_one({"author": "Stephen Hawking"}, new_book) # SOLUTION
UpdateResult({'n': 1, 'electionId': ObjectId('7fffffff00000000000000cb'), 'opTime': {'ts': Timestamp(1727120657, 2), 't': 203}, 'nModified': 1, 'ok': 1.0, '$clusterTime': {'clusterTime': Timestamp(1727120657, 2), 'signature': {'hash': b'[\x84\x00\xdc\xb3\x1e\xd6\x8b!?\x01\x08\xdfQ\xe9\x195\xdd\x16\xad', 'keyId': 7381891571605569538}}, 'operationTime': Timestamp(1727120657, 2), 'updatedExisting': True}, acknowledged=True)
# print out the document by Stephen Hawking
books.find_one({"author": "Stephen Hawking"}) # SOLUTION
{'_id': ObjectId('66f1c50f2a1f550705a4f5d8'),
'title': 'The Universe in a Nutshell',
'author': 'Stephen Hawking',
'genre': 'Non-Fiction',
'price': 12.99,
'publisher': 'Bantam Books'}
assert books.find_one({"title": "The Universe in a Nutshell"}) is not None, "The Universe in a Nutshell is not in the collection"
Exercise 4: Delete#
Let’s say I want to delete all documents in the students collection where their age is above 21
# Step 1: Define the filter to find the documents to be deleted
filter = {"age": {"$gt": 21}}
# Step 2: Delete the documents
result = students.delete_many(filter)
# Step 3: Print the number of documents deleted
print(result.deleted_count, " documents deleted.")
# check if the documents were deleted
for student in students.find():
print(student)
8 documents deleted.
{'_id': ObjectId('66e8885dc48457d8d5b1262c'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66e8885dc48457d8d5b1262d'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12631'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12632'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66e88869c48457d8d5b12636'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66e8970fc48457d8d5b12655'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66e8970fc48457d8d5b12656'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b1265d'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b1265e'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66e89710c48457d8d5b12662'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4df2a1f550705a4f5b7'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66f1c4df2a1f550705a4f5b8'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5bf'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5c0'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66f1c4e02a1f550705a4f5c4'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d3'), 'name': 'Alice', 'age': 20, 'major': 'Computer Science', 'gpa': None}
{'_id': ObjectId('66f1c50f2a1f550705a4f5d4'), 'name': 'Bob', 'age': 21, 'major': 'Mathematics', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5db'), 'name': 'Charlie Brown', 'age': 20, 'major': 'Physics', 'email': 'charlie.brown@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5dc'), 'name': 'Diana Prince', 'age': 21, 'major': 'History', 'email': 'diana.prince@example.com', 'gpa': None}
{'_id': ObjectId('66f1c5102a1f550705a4f5e0'), 'name': 'Hank Pym', 'age': 21, 'major': 'Biochemistry', 'email': 'hank.pym@example.com', 'gpa': None}
Now it’s your turn.
Delete all the documents in the books collection where the title start with letter “T”
Hint: You can use regex expression in the filter. For example, if I want all students start with letter “M”, I would use
filter = {"name": {"$regex": "^M"}}
# Delete all the documents in the `books` collection where the `title` start with letter "T"
# YOUR CODE HERE
# BEGIN SOLUTION
filter = {"title": {"$regex": "^T"}}
result = books.delete_many(filter)
# END SOLUTION
# Print the number of documents deleted
print(result.deleted_count, " documents deleted.") # SOLUTION
7 documents deleted.
# check if the documents were deleted
# find all books that start with letter "T"
for book in books.find({"title": {"$regex": "^T"}}): # SOLUTION
print(book) # SOLUTION
# print all the documents in the collection
for book in books.find(): # SOLUTION
print(book) # SOLUTION
{'_id': ObjectId('66f1c5102a1f550705a4f5e4'), 'title': '1984', 'author': 'George Orwell', 'published_year': 1949, 'isbn': '978-0-452-28423-4', 'price': 8.99, 'publisher': 'Unknown'}
{'_id': ObjectId('66f1c5102a1f550705a4f5e5'), 'title': 'Pride and Prejudice', 'author': 'Jane Austen', 'published_year': 1813, 'isbn': '978-0-19-953556-9', 'price': 12.99, 'publisher': 'Unknown'}
{'_id': ObjectId('66f1c5102a1f550705a4f5e7'), 'title': 'Moby-Dick', 'author': 'Herman Melville', 'published_year': 1851, 'isbn': '978-0-14-243724-7', 'price': 11.99, 'publisher': 'Unknown'}
{'_id': ObjectId('66f1c5102a1f550705a4f5e8'), 'title': 'War and Peace', 'author': 'Leo Tolstoy', 'published_year': 1869, 'isbn': '978-0-14-044793-4', 'price': 14.99, 'publisher': 'Unknown'}
{'_id': ObjectId('66f1c5102a1f550705a4f5eb'), 'title': 'Fahrenheit 451', 'author': 'Ray Bradbury', 'published_year': 1953, 'isbn': '978-0-7432-4722-2', 'price': 9.49, 'publisher': 'Penguin Books'}
{'_id': ObjectId('66f1c5102a1f550705a4f5ec'), 'title': 'Jane Eyre', 'author': 'Charlotte Brontë', 'published_year': 1847, 'isbn': '978-0-14-243720-9', 'price': 8.49, 'publisher': 'Unknown'}
# assert there are no documents that start with letter "T"
assert books.find_one({"title": {"$regex": "^T"}}) is None, "There are documents that start with letter T"
Exercise 5: Visualize#
Let’s say that we are retriving students data and we want to convert the results to pandas DataFrame
import pandas as pd
# Step 2: Query all documents in the collection
cursor = students.find()
# Step 3: Convert the cursor to a list and then to a DataFrame
students_data = list(cursor)
df = pd.DataFrame(students_data)
# Print the DataFrame to verify
df.head()
| _id | name | age | major | gpa | ||
|---|---|---|---|---|---|---|
| 0 | 66e8885dc48457d8d5b1262c | Alice | 20 | Computer Science | None | NaN |
| 1 | 66e8885dc48457d8d5b1262d | Bob | 21 | Mathematics | None | NaN |
| 2 | 66e88869c48457d8d5b12631 | Charlie Brown | 20 | Physics | None | charlie.brown@example.com |
| 3 | 66e88869c48457d8d5b12632 | Diana Prince | 21 | History | None | diana.prince@example.com |
| 4 | 66e88869c48457d8d5b12636 | Hank Pym | 21 | Biochemistry | None | hank.pym@example.com |
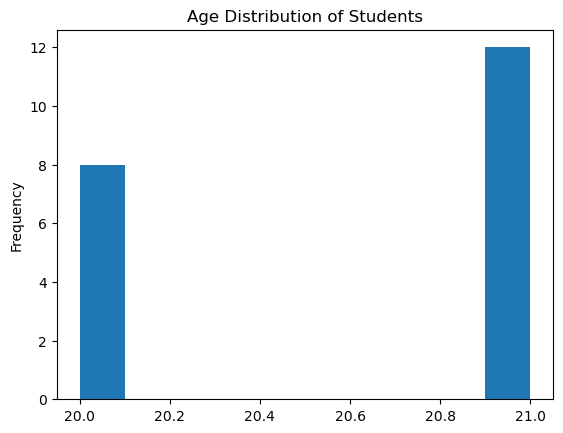
Now let’s create a simple bar chart of students’ age
import matplotlib.pyplot as plt
# create a histogram of students age
df['age'].plot(kind='hist', title='Age Distribution of Students')
<Axes: title={'center': 'Age Distribution of Students'}, ylabel='Frequency'>
Now it’s your turn
Convert the
bookscollection into a pd.Dataframe calleddf_booksCreate a histogram of books’ prices
# Convert the `books` collection into a pd.Dataframe called `df_books`
# YOUR CODE HERE
# BEGIN SOLUTION
cursor = books.find()
books_data = list(cursor)
df_books = pd.DataFrame(books_data)
df_books
# END SOLUTION
| _id | title | author | published_year | isbn | price | publisher | |
|---|---|---|---|---|---|---|---|
| 0 | 66f1c5102a1f550705a4f5e4 | 1984 | George Orwell | 1949 | 978-0-452-28423-4 | 8.99 | Unknown |
| 1 | 66f1c5102a1f550705a4f5e5 | Pride and Prejudice | Jane Austen | 1813 | 978-0-19-953556-9 | 12.99 | Unknown |
| 2 | 66f1c5102a1f550705a4f5e7 | Moby-Dick | Herman Melville | 1851 | 978-0-14-243724-7 | 11.99 | Unknown |
| 3 | 66f1c5102a1f550705a4f5e8 | War and Peace | Leo Tolstoy | 1869 | 978-0-14-044793-4 | 14.99 | Unknown |
| 4 | 66f1c5102a1f550705a4f5eb | Fahrenheit 451 | Ray Bradbury | 1953 | 978-0-7432-4722-2 | 9.49 | Penguin Books |
| 5 | 66f1c5102a1f550705a4f5ec | Jane Eyre | Charlotte Brontë | 1847 | 978-0-14-243720-9 | 8.49 | Unknown |
# visualize the distribution of book prices
df_books['price'].plot(kind='hist', title='Price Distribution of Books') # SOLUTION
<Axes: title={'center': 'Price Distribution of Books'}, ylabel='Frequency'>
# assert the dataframe was created
assert df_books is not None, "df_books does not exist"
# assert the dataframe has the correct columns
assert "title" in df_books.columns, "title column is missing"
assert "author" in df_books.columns, "author column is missing"
assert "price" in df_books.columns, "price column is missing"
Submission instructions#
{rubric: mechanics = 5}
Make sure the notebook can run from top to bottom without any error. Restart the kernel and run all cells.
Commit and push your notebook to the github repo
Double check your notebook is rendered properly on Github and you can see all the outputs clearly