Lecture 9: Introduction to PySpark#
Learning Objectives#
By the end of this lecture, students should be able to:
Understand what is Spark and its main components
How Spark is different from Hadoop’s Map Reduce
What are the key use case of Spark
Set up a databricks workspace
Apache Spark - An unified engine for large-scale analysis#
Apache Spark is an unified analytics engine designed for large-scale data processing. It offers high-level APIs in Java, Scala, Python, and R, along with an optimized engine that supports general execution graphs. Additionally, Spark includes a robust suite of higher-level tools such as Spark SQL for SQL and structured data processing, pandas API on Spark for handling pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.

Key benefits of Spark:#
Speed
Engineered from the bottom-up for performance, Spark can be 100x faster than Hadoop for large scale data processing by exploiting in memory computing and other optimizations. Spark is also fast when data is stored on disk, and currently holds the world record for large-scale on-disk sorting.
Ease of Use
Spark has easy-to-use APIs for operating on large datasets. This includes a collection of over 100 operators for transforming data and familiar data frame APIs for manipulating semi-structured data.
A Unified Engine
Spark comes packaged with higher-level libraries, including support for SQL queries, streaming data, machine learning and graph processing. These standard libraries increase developer productivity and can be seamlessly combined to create complex workflows.

The big idea behind distributed computing#
Distributed computing is a model in which components of a software system are shared among multiple computers to improve efficiency and performance. To understand this concept, let’s use the analogy of searching through a yellow phone book.
The Yellow Phone Book Analogy#
Imagine you have a massive yellow phone book with millions of entries, and you need to find the phone number of a specific person. Doing this task alone would be time-consuming and tedious. Now, let’s break down how distributed computing can make this process faster and more efficient.

Single Worker (Non-Distributed Computing)#
Scenario: One person (a single computer) is tasked with finding the phone number.
Process: The person starts from the first page and goes through each entry sequentially until they find the desired phone number.
Time: This process can take a long time, especially if the phone book is enormous.
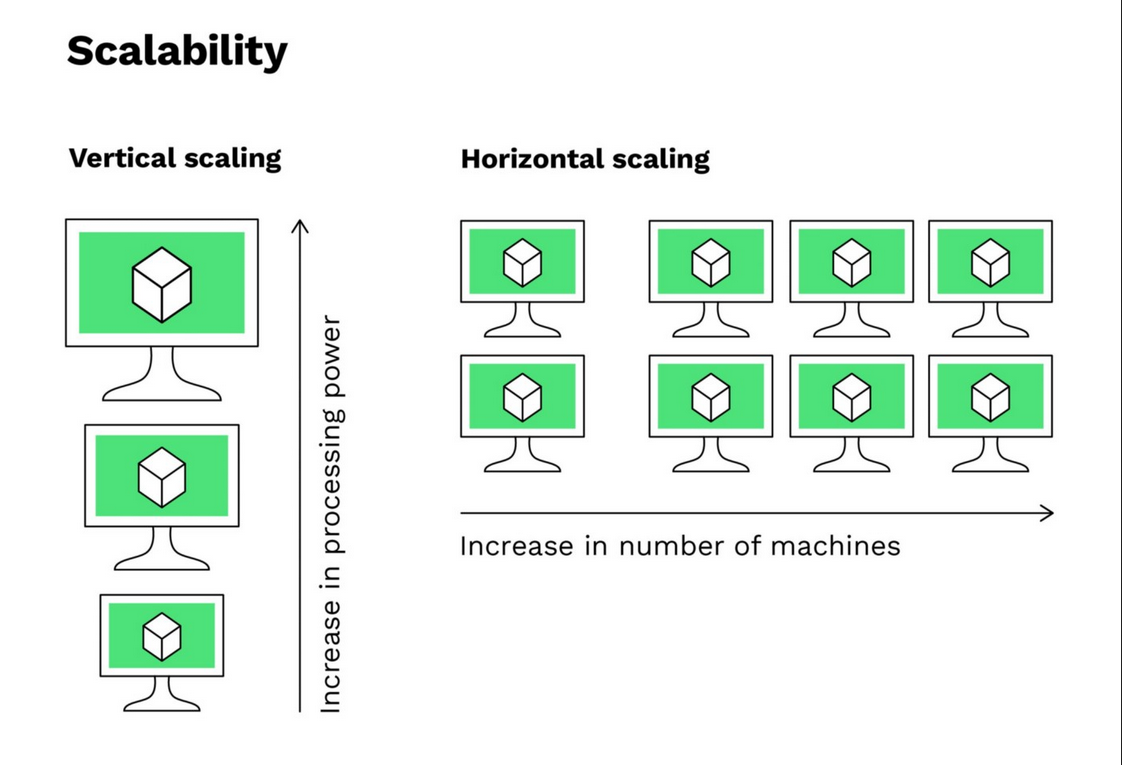
Vertical scaling: Enhancing the capabilities of a single computer by adding more CPU, memory, or faster storage.
Multiple Workers (Distributed Computing)#
Scenario: You have a team of people (multiple computers) to help you search through the phone book.
Process:
Divide the Task: Split the phone book into equal sections and assign each section to a different person.
Parallel Search: Each person searches their assigned section simultaneously.
Combine Results: Once a person finds the phone number, they inform the rest of the team, and the search stops.
Time: The search process is significantly faster because multiple sections are being searched at the same time.
Horizontal scaling: Adding more computers to the system to share the workload.
Key Concepts in Distributed Computing#
Parallelism: Just like multiple people searching different sections of the phone book simultaneously, distributed computing involves multiple processors working on different parts of a task at the same time.
Scalability: Adding more workers (computers) can further speed up the search process. Similarly, distributed systems can scale by adding more nodes to handle larger workloads.
Fault Tolerance: If one person gets tired or makes a mistake, others can continue the search. In distributed computing, if one node fails, other nodes can take over its tasks, ensuring the system remains operational.
Coordination: Effective communication and coordination are essential. In our analogy, workers need to inform each other when the phone number is found. In distributed systems, nodes must coordinate to share data and results.
Spark and Hadoop’s ecosystem#
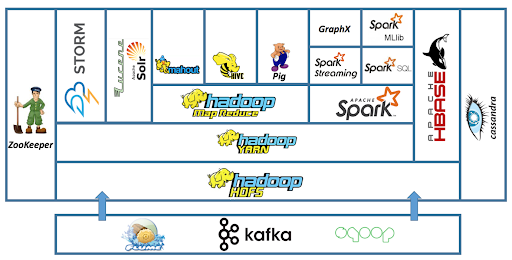
Credit: https://tutorials.freshersnow.com/hadoop-tutorial/hadoop-ecosystem-components/
Hadoop Ecosystem#
Hadoop Distributed File System (HDFS): is a special file system that stores large datasets across multiple computers. These computers are called Hadoop clusters.
MapReduce: allows programs to break large data processing tasks into smaller ones and runs them in parallel on multiple servers.
YARN (Yet Another Resource Negotiator): schedules tasks and allocates resources to applications running on Hadoop.
Spark Ecosystem#
Spark Core: The foundation of the Spark framework, responsible for basic I/O functionalities, task scheduling, and memory management.
Spark SQL: Allows querying of structured data via SQL and supports integration with various data sources.
Spark Streaming: Enables real-time data processing and analytics.
MLlib: A library for scalable machine learning algorithms.
GraphX: A library for graph processing and analysis.
SparkR: An R package that provides a lightweight frontend to use Apache Spark from R.
Key Differences: Hadoop vs. Spark#
Hadoop |
Spark |
|
|---|---|---|
Architecture |
Hadoop stores and processes data on external storage. |
Spark stores and process data on internal memory. |
Performance |
Hadoop processes data in batches. |
Spark processes data in real time. |
Cost |
Hadoop is affordable. |
Spark is comparatively more expensive. |
Scalability |
Hadoop is easily scalable by adding more nodes. |
Spark is comparatively more challenging. |
Machine learning |
Hadoop integrates with external libraries to provide machine learning capabilities. |
Spark has built-in machine learning libraries. |
Security |
Hadoop has strong security features, storage encryption, and access control. |
Spark has basic security. IT relies on you setting up a secure operating environment for the Spark deployment. |
Hadoop use cases#
Hadoop is most effective for scenarios that involve the following:
Processing big data sets in environments where data size exceeds available memory
Batch processing with tasks that exploit disk read and write operations
Building data analysis infrastructure with a limited budget
Completing jobs that are not time-sensitive
Historical and archive data analysis
Spark use cases#
Spark is most effective for scenarios that involve the following:
Dealing with chains of parallel operations by using iterative algorithms
Achieving quick results with in-memory computations
Analyzing stream data analysis in real time
Graph-parallel processing to model data
All ML applications
Spark and Databricks#
Introduction to Databricks#
Databricks: A cloud-based platform designed to simplify big data processing and analytics. It was founded by the creators of Apache Spark and provides a unified environment for data engineering, data science, and machine learning.
Key Features of Databricks#
Managed Spark Environment: Databricks offers a fully managed Spark environment, which simplifies the deployment, management, and scaling of Spark applications.
Collaborative Workspace: Provides a collaborative workspace where data engineers, data scientists, and analysts can work together on data projects.
Optimized Spark Engine: Includes performance optimizations over open-source Spark, making it faster and more efficient.
Integrated Machine Learning: Simplifies the process of building, training, and deploying machine learning models.
Interactive Notebooks: Supports interactive notebooks that allow users to write code, visualize data, and share insights in a single document.
Relation to Apache Spark#
Founders: Databricks was founded by the original creators of Apache Spark, ensuring deep integration and optimization for Spark workloads.
Enhanced Spark Capabilities: Databricks enhances Spark’s capabilities by providing additional features such as optimized performance, collaborative tools, and integrated machine learning.
Unified Analytics Platform: Combines the power of Spark with additional tools and services to create a comprehensive platform for big data analytics and machine learning.
Benefits of Using Databricks with Spark#
Ease of Use: Simplifies the setup and management of Spark clusters, allowing users to focus on data processing and analysis.
Scalability: Automatically scales resources based on workload demands, ensuring efficient use of resources.
Performance: Provides performance improvements over open-source Spark, making data processing faster and more efficient.
Collaboration: Facilitates collaboration among team members through shared notebooks and integrated workflows.
Security: Offers robust security features, including data encryption, access controls, and compliance with industry standards.
Sign up for Databricks Community edition#
Click Try Databricks here
Enter your name, company, email, and title, and click Continue.
On the Choose a cloud provider dialog, click the Get started with Community Edition link. You’ll see a page announcing that an email has been sent to the address you provided.
Look for the welcome email and click the link to verify your email address. You are prompted to create your Databricks password.
When you click Submit, you’ll be taken to the Databricks Community Edition home page
Getting started with PySpark on databricks#
Spark session
A Spark session is the entry point to programming with Spark. It allows you to create DataFrames, register DataFrames as tables, execute SQL queries, and read data from various sources
You initialize a Spark session using SparkSession.builder. The appName method sets the name of your application, which can be useful for debugging and monitoring.
from pyspark.sql import SparkSession
# Initialize Spark Session
spark = SparkSession.builder.appName("DataFrame Example").getOrCreate()
spark
SparkSession - hive
# Create a DataFrame from a list of tuples
data = [(1, "Alice"), (2, "Bob"), (3, "Cathy")]
columns = ["id", "name"]
df = spark.createDataFrame(data, columns)
# show data using databrick display function
display(df)
| id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Cathy |
# show data using pyspark show() function
df.show()
+---+-----+
| id| name|
+---+-----+
| 1|Alice|
| 2| Bob|
| 3|Cathy|
+---+-----+