Topic: Transitioning from simple Linear Regression to Multi-Layer Perceptrons (MLP). Goal: Understand why we add “hidden layers” and “activation functions” to build deep learning models.
1. Recap: The Linear Model¶
Also known as: Single-Layer Perceptron or Logistic Regression (in classification).
In our previous tutorial, we built a model that took an input (an image) and directly predicted the output (a digit).
The Architecture¶
Imagine our MNIST task. We have 784 inputs () (pixels) and 10 outputs () (digit classes). In a linear model, every input pixel has a “weight” () connected directly to every output class.
Input vector (Size: 784)
Weight matrix (Size: 10 x 784)
Bias vector (Size: 10)
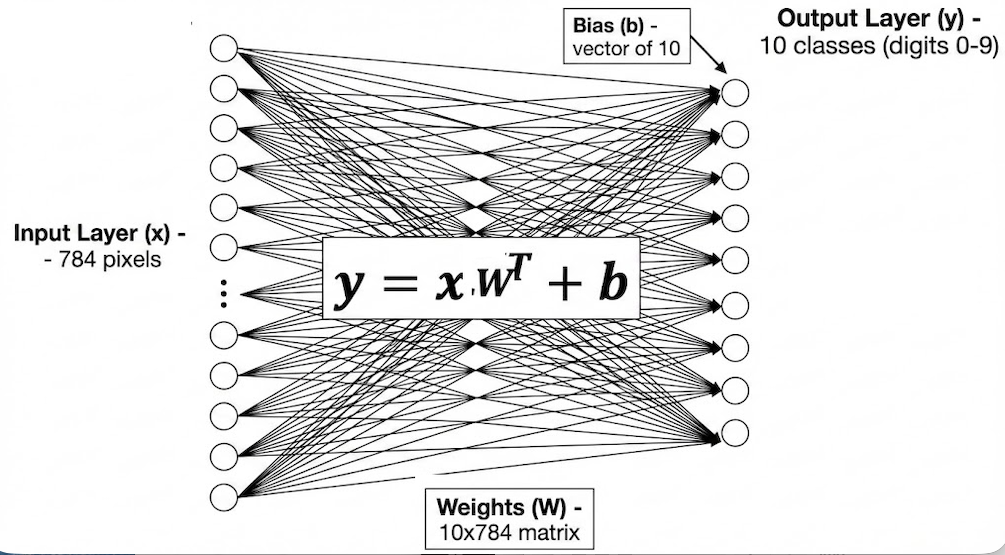
The Limitation¶
This model is Linear. It can only draw straight lines (or hyperplanes) to separate data.
If the data is “linearly separable” (e.g., all 0s are on the left, all 1s are on the right), it works great.
Real world problem: Handwriting is messy. The relationship between a pixel in the corner and the number “8” is complex and curvy, not straight. A linear model effectively “underfits” complex data.
2. Adding a Hidden Layer¶
To solve the limitation of straight lines, we insert a new layer of neurons in between the input and the output. This is called a Hidden Layer.
The New Architecture¶
Instead of going Input --> Output , we go Input --> Hidden --> Output.
Input Layer: 784 Neurons (The raw pixels)
Hidden Layer: 32 Neurons (Learns intermediate features, like edges or loops)
Output Layer: 10 Neurons (The final class probabilities)
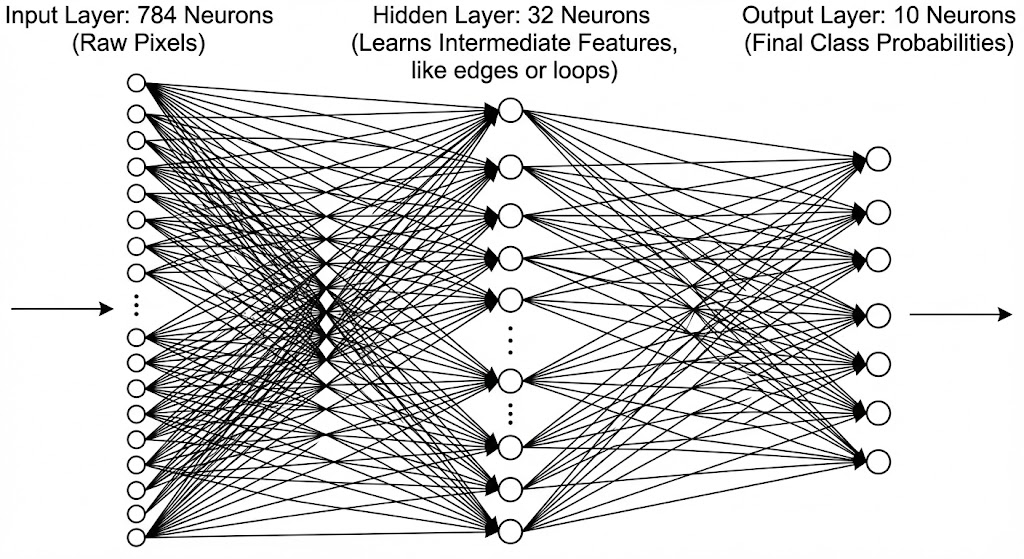
The Math¶
If we just stack two linear equations, look what happens:
Substitute into the second equation:
3. The Activation Function¶
To fix the problem above, we apply a Non-Linear Activation Function (denoted as ) to the output of the hidden layer.
Because of , the layers no longer collapse into a single matrix. The network can now learn curves, twists, and complex shapes.
Common Activation Functions¶
A. Sigmoid ()¶
Formula:
Shape: S-curve. Squishes numbers between 0 and 1.
Pros: Smooth, interpretable as probability.
Cons: Vanishing Gradient. For very high or low numbers, the slope is near zero. The network stops learning deep in the layers. (Old school, rarely used for hidden layers now).
B. ReLU (Rectified Linear Unit)¶
Formula:
Shape: If negative, it’s 0. If positive, it’s just .
Pros: Extremely computationally fast. Solves the Vanishing Gradient problem for positive numbers.
Cons: “Dead ReLU” problem (if a neuron gets stuck in the negative side, it never updates again).
Verdict: The default choice for modern Deep Learning.
C. Tanh (Hyperbolic Tangent)¶
Formula:
Shape: S-curve. Outputs values between -1 and 1.
Pros: Zero-centered output, which can help optimization.
Cons: Still suffers from the vanishing gradient problem for large positive or negative values.
Verdict: Often used in hidden layers of older neural networks, less common
D. Softmax¶
Use case: Only for the Output Layer in classification.
Function: Turns raw numbers (logits) into probabilities that sum to 100%.
Source
import numpy as np
import matplotlib.pyplot as plt
# Define activation functions
def sigmoid(x): return 1 / (1 + np.exp(-x))
def tanh(x): return np.tanh(x)
def relu(x): return np.maximum(0, x)
def leaky_relu(x, alpha=0.1): return np.where(x > 0, x, x * alpha)
# Setup data
x = np.linspace(-4, 4, 400)
# Activation formulas for annotation
formulas = {
'Sigmoid': r'$\sigma(x) = \frac{1}{1 + e^{-x}}$',
'Tanh': r'$\tanh(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}$',
'ReLU': r'$\mathrm{ReLU}(x) = \max(0, x)$',
'Leaky ReLU': r'$\mathrm{LeakyReLU}(x) = \max(0.01x, x)$'
}
# Create Plot
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
plt.subplots_adjust(hspace=0.3)
fig.suptitle('Common Neural Network Activation Functions', fontsize=16, fontweight='bold')
# Plot configurations
configs = [
(axes[0,0], sigmoid, 'Sigmoid', 'Output: (0, 1)'),
(axes[0,1], tanh, 'Tanh', 'Output: (-1, 1)'),
(axes[1,0], relu, 'ReLU', 'Output: [0, inf)'),
(axes[1,1], leaky_relu, 'Leaky ReLU', 'Output: (-inf, inf)')
]
for ax, func, title, note in configs:
ax.plot(x, func(x), label='Activation', color='blue', linewidth=2)
# Styling
ax.set_title(f"{title}\n{note}")
ax.grid(True, alpha=0.3)
ax.axhline(0, color='black', linewidth=1)
ax.axvline(0, color='black', linewidth=1)
ax.legend()
# Add formula annotation
ax.text(
0.05, 0.92, formulas[title],
transform=ax.transAxes,
fontsize=13,
verticalalignment='top',
bbox=dict(boxstyle='round,pad=0.3', facecolor='white', alpha=0.7)
)
# Specific y-limits for clarity
if title == 'Sigmoid': ax.set_ylim(-0.2, 1.2)
elif title == 'Tanh': ax.set_ylim(-1.2, 1.2)
elif title == 'ReLU': ax.set_ylim(-1, 4)
elif title == 'Leaky ReLU': ax.set_ylim(-1, 4)
plt.show()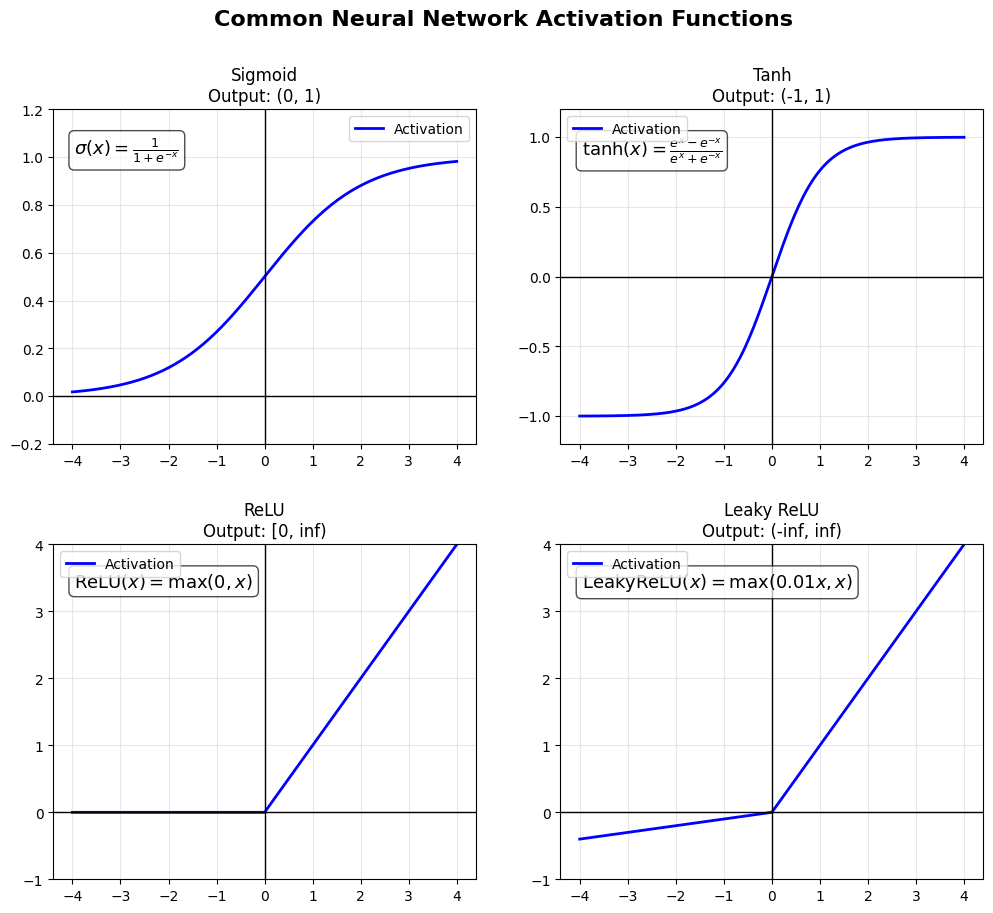
4. PyTorch Implementation Recap¶
Here is how these three concepts (Linear Layers, Hidden Layers, Activation Functions) look in code using nn.Sequential.
1. Setup and Data Splitting¶
We split the 60,000 training images into 50,000 for Training and 10,000 for Validation.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as pltimport torch
if torch.backends.mps.is_available():
device = torch.device("mps")
print("Using MPS device")
else:
device = torch.device("cpu")
print("MPS not available, using CPU")
Using MPS device
# 1. Define Transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 2. Download Full Training Data
full_train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)# 3. Split into Train (50k) and Validation (10k)
# Validation is used to tune hyperparameters and check for overfitting
train_size = 50000
val_size = 10000
train_dataset, val_dataset = random_split(full_train_dataset, [train_size, val_size])
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 10, figsize=(15, 2))
for i in range(10):
image, label = train_dataset[i]
axes[i].imshow(image.squeeze(), cmap='gray')
axes[i].set_title(label)
axes[i].axis('off')
plt.show()
# 4. Create Loaders
batch_size = 1024
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4, # Use 4 CPU cores to prepare data
persistent_workers=True # Keep workers alive between epochs # Fast transfer to MPS/GPU
)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=batch_size, # Validation can also be large batch
shuffle=False,
num_workers=4,
persistent_workers=True
)2. The Sequential Model¶
class SimpleNetSequential(nn.Module):
def __init__(self):
super().__init__()
self.network = nn.Sequential(
nn.Flatten(), # Flatten 28x28 -> 784
nn.Linear(784, 32), # Hidden Layer
nn.ReLU(), # Activation
nn.Linear(32, 10) # Output Layer
)
def forward(self, x):
return self.network(x)
# Initialize Model
model = SimpleNetSequential().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
print(model)SimpleNetSequential(
(network): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=32, bias=True)
(2): ReLU()
(3): Linear(in_features=32, out_features=10, bias=True)
)
)
# Count the number of parameters in your model
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print("Total trainable parameters:", count_parameters(model))Total trainable parameters: 25450
for name, param in model.named_parameters():
if param.requires_grad:
print(f"{name}: {param.shape}")network.1.weight: torch.Size([32, 784])
network.1.bias: torch.Size([32])
network.3.weight: torch.Size([10, 32])
network.3.bias: torch.Size([10])
3. Training Loop with Validation Tracking¶
We track both losses. Note the critical use of model.train() and model.eval().
num_epochs = 200
# Lists to store metrics for plotting
train_losses = []
val_losses = []
print("Starting Training...")
for epoch in range(num_epochs):
# --- TRAINING PHASE ---
model.train() # Turn Dropout ON
running_train_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_train_loss += loss.item()
# Calculate average training loss for this epoch
avg_train_loss = running_train_loss / len(train_loader)
train_losses.append(avg_train_loss)
# --- VALIDATION PHASE ---
model.eval() # Turn Dropout OFF
running_val_loss = 0.0
with torch.no_grad(): # No gradients needed for validation
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_val_loss += loss.item()
# Calculate average validation loss for this epoch
avg_val_loss = running_val_loss / len(val_loader)
val_losses.append(avg_val_loss)
print(f"Epoch [{epoch+1}/{num_epochs}] | Train Loss: {avg_train_loss:.4f} | Val Loss: {avg_val_loss:.4f}")
print("Training Finished!")
Starting Training...
Epoch [1/200] | Train Loss: 1.3597 | Val Loss: 0.7080
Epoch [2/200] | Train Loss: 0.5506 | Val Loss: 0.4593
Epoch [3/200] | Train Loss: 0.4157 | Val Loss: 0.3932
Epoch [4/200] | Train Loss: 0.3670 | Val Loss: 0.3647
Epoch [5/200] | Train Loss: 0.3385 | Val Loss: 0.3387
Epoch [6/200] | Train Loss: 0.3186 | Val Loss: 0.3287
Epoch [7/200] | Train Loss: 0.3048 | Val Loss: 0.3182
Epoch [8/200] | Train Loss: 0.2933 | Val Loss: 0.3074
Epoch [9/200] | Train Loss: 0.2822 | Val Loss: 0.3007
Epoch [10/200] | Train Loss: 0.2742 | Val Loss: 0.2919
Epoch [11/200] | Train Loss: 0.2647 | Val Loss: 0.2885
Epoch [12/200] | Train Loss: 0.2566 | Val Loss: 0.2783
Epoch [13/200] | Train Loss: 0.2500 | Val Loss: 0.2771
Epoch [14/200] | Train Loss: 0.2406 | Val Loss: 0.2687
Epoch [15/200] | Train Loss: 0.2333 | Val Loss: 0.2646
Epoch [16/200] | Train Loss: 0.2287 | Val Loss: 0.2593
Epoch [17/200] | Train Loss: 0.2202 | Val Loss: 0.2532
Epoch [18/200] | Train Loss: 0.2126 | Val Loss: 0.2489
Epoch [19/200] | Train Loss: 0.2086 | Val Loss: 0.2447
Epoch [20/200] | Train Loss: 0.2016 | Val Loss: 0.2390
Epoch [21/200] | Train Loss: 0.1959 | Val Loss: 0.2352
Epoch [22/200] | Train Loss: 0.1903 | Val Loss: 0.2325
Epoch [23/200] | Train Loss: 0.1858 | Val Loss: 0.2273
Epoch [24/200] | Train Loss: 0.1817 | Val Loss: 0.2231
Epoch [25/200] | Train Loss: 0.1770 | Val Loss: 0.2202
Epoch [26/200] | Train Loss: 0.1731 | Val Loss: 0.2190
Epoch [27/200] | Train Loss: 0.1694 | Val Loss: 0.2182
Epoch [28/200] | Train Loss: 0.1657 | Val Loss: 0.2139
Epoch [29/200] | Train Loss: 0.1627 | Val Loss: 0.2093
Epoch [30/200] | Train Loss: 0.1584 | Val Loss: 0.2060
Epoch [31/200] | Train Loss: 0.1553 | Val Loss: 0.2046
Epoch [32/200] | Train Loss: 0.1519 | Val Loss: 0.2014
Epoch [33/200] | Train Loss: 0.1499 | Val Loss: 0.2006
Epoch [34/200] | Train Loss: 0.1458 | Val Loss: 0.1986
Epoch [35/200] | Train Loss: 0.1428 | Val Loss: 0.1957
Epoch [36/200] | Train Loss: 0.1408 | Val Loss: 0.1948
Epoch [37/200] | Train Loss: 0.1381 | Val Loss: 0.1905
Epoch [38/200] | Train Loss: 0.1356 | Val Loss: 0.1903
Epoch [39/200] | Train Loss: 0.1325 | Val Loss: 0.1906
Epoch [40/200] | Train Loss: 0.1302 | Val Loss: 0.1889
Epoch [41/200] | Train Loss: 0.1283 | Val Loss: 0.1857
Epoch [42/200] | Train Loss: 0.1263 | Val Loss: 0.1854
Epoch [43/200] | Train Loss: 0.1251 | Val Loss: 0.1875
Epoch [44/200] | Train Loss: 0.1230 | Val Loss: 0.1846
Epoch [45/200] | Train Loss: 0.1212 | Val Loss: 0.1824
Epoch [46/200] | Train Loss: 0.1178 | Val Loss: 0.1814
Epoch [47/200] | Train Loss: 0.1167 | Val Loss: 0.1829
Epoch [48/200] | Train Loss: 0.1154 | Val Loss: 0.1827
Epoch [49/200] | Train Loss: 0.1144 | Val Loss: 0.1809
Epoch [50/200] | Train Loss: 0.1130 | Val Loss: 0.1744
Epoch [51/200] | Train Loss: 0.1111 | Val Loss: 0.1764
Epoch [52/200] | Train Loss: 0.1090 | Val Loss: 0.1728
Epoch [53/200] | Train Loss: 0.1081 | Val Loss: 0.1718
Epoch [54/200] | Train Loss: 0.1068 | Val Loss: 0.1786
Epoch [55/200] | Train Loss: 0.1054 | Val Loss: 0.1724
Epoch [56/200] | Train Loss: 0.1037 | Val Loss: 0.1712
Epoch [57/200] | Train Loss: 0.1025 | Val Loss: 0.1701
Epoch [58/200] | Train Loss: 0.1004 | Val Loss: 0.1720
Epoch [59/200] | Train Loss: 0.1006 | Val Loss: 0.1698
Epoch [60/200] | Train Loss: 0.0992 | Val Loss: 0.1696
Epoch [61/200] | Train Loss: 0.0969 | Val Loss: 0.1667
Epoch [62/200] | Train Loss: 0.0966 | Val Loss: 0.1725
Epoch [63/200] | Train Loss: 0.0960 | Val Loss: 0.1667
Epoch [64/200] | Train Loss: 0.0945 | Val Loss: 0.1672
Epoch [65/200] | Train Loss: 0.0926 | Val Loss: 0.1671
Epoch [66/200] | Train Loss: 0.0928 | Val Loss: 0.1699
Epoch [67/200] | Train Loss: 0.0911 | Val Loss: 0.1658
Epoch [68/200] | Train Loss: 0.0909 | Val Loss: 0.1640
Epoch [69/200] | Train Loss: 0.0889 | Val Loss: 0.1647
Epoch [70/200] | Train Loss: 0.0879 | Val Loss: 0.1647
Epoch [71/200] | Train Loss: 0.0883 | Val Loss: 0.1654
Epoch [72/200] | Train Loss: 0.0864 | Val Loss: 0.1685
Epoch [73/200] | Train Loss: 0.0873 | Val Loss: 0.1677
Epoch [74/200] | Train Loss: 0.0851 | Val Loss: 0.1676
Epoch [75/200] | Train Loss: 0.0837 | Val Loss: 0.1677
Epoch [76/200] | Train Loss: 0.0834 | Val Loss: 0.1663
Epoch [77/200] | Train Loss: 0.0826 | Val Loss: 0.1633
Epoch [78/200] | Train Loss: 0.0810 | Val Loss: 0.1644
Epoch [79/200] | Train Loss: 0.0817 | Val Loss: 0.1677
Epoch [80/200] | Train Loss: 0.0795 | Val Loss: 0.1629
Epoch [81/200] | Train Loss: 0.0781 | Val Loss: 0.1639
Epoch [82/200] | Train Loss: 0.0779 | Val Loss: 0.1617
Epoch [83/200] | Train Loss: 0.0768 | Val Loss: 0.1624
Epoch [84/200] | Train Loss: 0.0766 | Val Loss: 0.1621
Epoch [85/200] | Train Loss: 0.0753 | Val Loss: 0.1623
Epoch [86/200] | Train Loss: 0.0747 | Val Loss: 0.1630
Epoch [87/200] | Train Loss: 0.0738 | Val Loss: 0.1638
Epoch [88/200] | Train Loss: 0.0749 | Val Loss: 0.1645
Epoch [89/200] | Train Loss: 0.0731 | Val Loss: 0.1649
Epoch [90/200] | Train Loss: 0.0725 | Val Loss: 0.1628
Epoch [91/200] | Train Loss: 0.0707 | Val Loss: 0.1608
Epoch [92/200] | Train Loss: 0.0701 | Val Loss: 0.1625
Epoch [93/200] | Train Loss: 0.0700 | Val Loss: 0.1667
Epoch [94/200] | Train Loss: 0.0698 | Val Loss: 0.1633
Epoch [95/200] | Train Loss: 0.0690 | Val Loss: 0.1663
Epoch [96/200] | Train Loss: 0.0683 | Val Loss: 0.1619
Epoch [97/200] | Train Loss: 0.0678 | Val Loss: 0.1630
Epoch [98/200] | Train Loss: 0.0664 | Val Loss: 0.1666
Epoch [99/200] | Train Loss: 0.0692 | Val Loss: 0.1670
Epoch [100/200] | Train Loss: 0.0676 | Val Loss: 0.1637
Epoch [101/200] | Train Loss: 0.0660 | Val Loss: 0.1663
Epoch [102/200] | Train Loss: 0.0641 | Val Loss: 0.1640
Epoch [103/200] | Train Loss: 0.0645 | Val Loss: 0.1641
Epoch [104/200] | Train Loss: 0.0639 | Val Loss: 0.1673
Epoch [105/200] | Train Loss: 0.0627 | Val Loss: 0.1669
Epoch [106/200] | Train Loss: 0.0634 | Val Loss: 0.1651
Epoch [107/200] | Train Loss: 0.0623 | Val Loss: 0.1660
Epoch [108/200] | Train Loss: 0.0612 | Val Loss: 0.1645
Epoch [109/200] | Train Loss: 0.0607 | Val Loss: 0.1634
Epoch [110/200] | Train Loss: 0.0617 | Val Loss: 0.1662
Epoch [111/200] | Train Loss: 0.0607 | Val Loss: 0.1661
Epoch [112/200] | Train Loss: 0.0595 | Val Loss: 0.1647
Epoch [113/200] | Train Loss: 0.0588 | Val Loss: 0.1697
Epoch [114/200] | Train Loss: 0.0600 | Val Loss: 0.1682
Epoch [115/200] | Train Loss: 0.0577 | Val Loss: 0.1667
Epoch [116/200] | Train Loss: 0.0579 | Val Loss: 0.1647
Epoch [117/200] | Train Loss: 0.0569 | Val Loss: 0.1691
Epoch [118/200] | Train Loss: 0.0570 | Val Loss: 0.1686
Epoch [119/200] | Train Loss: 0.0556 | Val Loss: 0.1727
Epoch [120/200] | Train Loss: 0.0558 | Val Loss: 0.1707
Epoch [121/200] | Train Loss: 0.0559 | Val Loss: 0.1687
Epoch [122/200] | Train Loss: 0.0538 | Val Loss: 0.1709
Epoch [123/200] | Train Loss: 0.0539 | Val Loss: 0.1708
Epoch [124/200] | Train Loss: 0.0536 | Val Loss: 0.1711
Epoch [125/200] | Train Loss: 0.0531 | Val Loss: 0.1696
Epoch [126/200] | Train Loss: 0.0538 | Val Loss: 0.1705
Epoch [127/200] | Train Loss: 0.0521 | Val Loss: 0.1749
Epoch [128/200] | Train Loss: 0.0527 | Val Loss: 0.1754
Epoch [129/200] | Train Loss: 0.0522 | Val Loss: 0.1750
Epoch [130/200] | Train Loss: 0.0517 | Val Loss: 0.1764
Epoch [131/200] | Train Loss: 0.0551 | Val Loss: 0.1744
Epoch [132/200] | Train Loss: 0.0509 | Val Loss: 0.1753
Epoch [133/200] | Train Loss: 0.0521 | Val Loss: 0.1724
Epoch [134/200] | Train Loss: 0.0498 | Val Loss: 0.1747
Epoch [135/200] | Train Loss: 0.0493 | Val Loss: 0.1763
Epoch [136/200] | Train Loss: 0.0492 | Val Loss: 0.1768
Epoch [137/200] | Train Loss: 0.0487 | Val Loss: 0.1739
Epoch [138/200] | Train Loss: 0.0477 | Val Loss: 0.1761
Epoch [139/200] | Train Loss: 0.0487 | Val Loss: 0.1786
Epoch [140/200] | Train Loss: 0.0476 | Val Loss: 0.1779
Epoch [141/200] | Train Loss: 0.0488 | Val Loss: 0.1788
Epoch [142/200] | Train Loss: 0.0467 | Val Loss: 0.1762
Epoch [143/200] | Train Loss: 0.0470 | Val Loss: 0.1779
Epoch [144/200] | Train Loss: 0.0451 | Val Loss: 0.1765
Epoch [145/200] | Train Loss: 0.0461 | Val Loss: 0.1770
Epoch [146/200] | Train Loss: 0.0458 | Val Loss: 0.1796
Epoch [147/200] | Train Loss: 0.0448 | Val Loss: 0.1782
Epoch [148/200] | Train Loss: 0.0443 | Val Loss: 0.1810
Epoch [149/200] | Train Loss: 0.0447 | Val Loss: 0.1822
Epoch [150/200] | Train Loss: 0.0437 | Val Loss: 0.1826
Epoch [151/200] | Train Loss: 0.0422 | Val Loss: 0.1830
Epoch [152/200] | Train Loss: 0.0430 | Val Loss: 0.1825
Epoch [153/200] | Train Loss: 0.0431 | Val Loss: 0.1812
Epoch [154/200] | Train Loss: 0.0429 | Val Loss: 0.1868
Epoch [155/200] | Train Loss: 0.0428 | Val Loss: 0.1875
Epoch [156/200] | Train Loss: 0.0414 | Val Loss: 0.1821
Epoch [157/200] | Train Loss: 0.0412 | Val Loss: 0.1834
Epoch [158/200] | Train Loss: 0.0424 | Val Loss: 0.1850
Epoch [159/200] | Train Loss: 0.0418 | Val Loss: 0.1873
Epoch [160/200] | Train Loss: 0.0420 | Val Loss: 0.1839
Epoch [161/200] | Train Loss: 0.0407 | Val Loss: 0.1895
Epoch [162/200] | Train Loss: 0.0412 | Val Loss: 0.1886
Epoch [163/200] | Train Loss: 0.0390 | Val Loss: 0.1874
Epoch [164/200] | Train Loss: 0.0395 | Val Loss: 0.1899
Epoch [165/200] | Train Loss: 0.0398 | Val Loss: 0.1924
Epoch [166/200] | Train Loss: 0.0399 | Val Loss: 0.1893
Epoch [167/200] | Train Loss: 0.0393 | Val Loss: 0.1909
Epoch [168/200] | Train Loss: 0.0396 | Val Loss: 0.1932
Epoch [169/200] | Train Loss: 0.0393 | Val Loss: 0.1903
Epoch [170/200] | Train Loss: 0.0384 | Val Loss: 0.1907
Epoch [171/200] | Train Loss: 0.0377 | Val Loss: 0.1899
Epoch [172/200] | Train Loss: 0.0368 | Val Loss: 0.1898
Epoch [173/200] | Train Loss: 0.0372 | Val Loss: 0.1965
Epoch [174/200] | Train Loss: 0.0393 | Val Loss: 0.1899
Epoch [175/200] | Train Loss: 0.0368 | Val Loss: 0.1913
Epoch [176/200] | Train Loss: 0.0371 | Val Loss: 0.1941
Epoch [177/200] | Train Loss: 0.0366 | Val Loss: 0.1940
Epoch [178/200] | Train Loss: 0.0351 | Val Loss: 0.1940
Epoch [179/200] | Train Loss: 0.0347 | Val Loss: 0.1997
Epoch [180/200] | Train Loss: 0.0375 | Val Loss: 0.1960
Epoch [181/200] | Train Loss: 0.0359 | Val Loss: 0.1940
Epoch [182/200] | Train Loss: 0.0341 | Val Loss: 0.1954
Epoch [183/200] | Train Loss: 0.0340 | Val Loss: 0.1991
Epoch [184/200] | Train Loss: 0.0344 | Val Loss: 0.1981
Epoch [185/200] | Train Loss: 0.0331 | Val Loss: 0.1981
Epoch [186/200] | Train Loss: 0.0342 | Val Loss: 0.2010
Epoch [187/200] | Train Loss: 0.0337 | Val Loss: 0.1974
Epoch [188/200] | Train Loss: 0.0332 | Val Loss: 0.2067
Epoch [189/200] | Train Loss: 0.0345 | Val Loss: 0.2006
Epoch [190/200] | Train Loss: 0.0321 | Val Loss: 0.2003
Epoch [191/200] | Train Loss: 0.0333 | Val Loss: 0.2026
Epoch [192/200] | Train Loss: 0.0314 | Val Loss: 0.1994
Epoch [193/200] | Train Loss: 0.0320 | Val Loss: 0.2042
Epoch [194/200] | Train Loss: 0.0312 | Val Loss: 0.2030
Epoch [195/200] | Train Loss: 0.0331 | Val Loss: 0.2093
Epoch [196/200] | Train Loss: 0.0319 | Val Loss: 0.2088
Epoch [197/200] | Train Loss: 0.0305 | Val Loss: 0.2034
Epoch [198/200] | Train Loss: 0.0305 | Val Loss: 0.2030
Epoch [199/200] | Train Loss: 0.0296 | Val Loss: 0.2107
Epoch [200/200] | Train Loss: 0.0309 | Val Loss: 0.2067
Training Finished!
4. Visualization: Training Loss vs. Validation Loss¶
This plot is the standard way to detect overfitting.
Ideal: Both lines go down together.
Overfitting: Blue line (Train) goes down, Orange line (Val) starts going up.
import plotly.express as px
import pandas as pd
# Prepare data
epochs = list(range(1, len(train_losses) + 1))
df = pd.DataFrame({
"Epoch": epochs * 2,
"Loss": train_losses + val_losses,
"Type": ["Training"] * len(train_losses) + ["Validation"] * len(val_losses)
})
# Create line plot
fig = px.line(df, x="Epoch", y="Loss", color="Type", title="Training vs. Validation Loss")
fig.show()5. Overfitting and regularization¶
Overfitting occurs when a neural network learns the training data too well, including its noise, and fails to generalize to new data. Regularization techniques help prevent this. Common methods include:
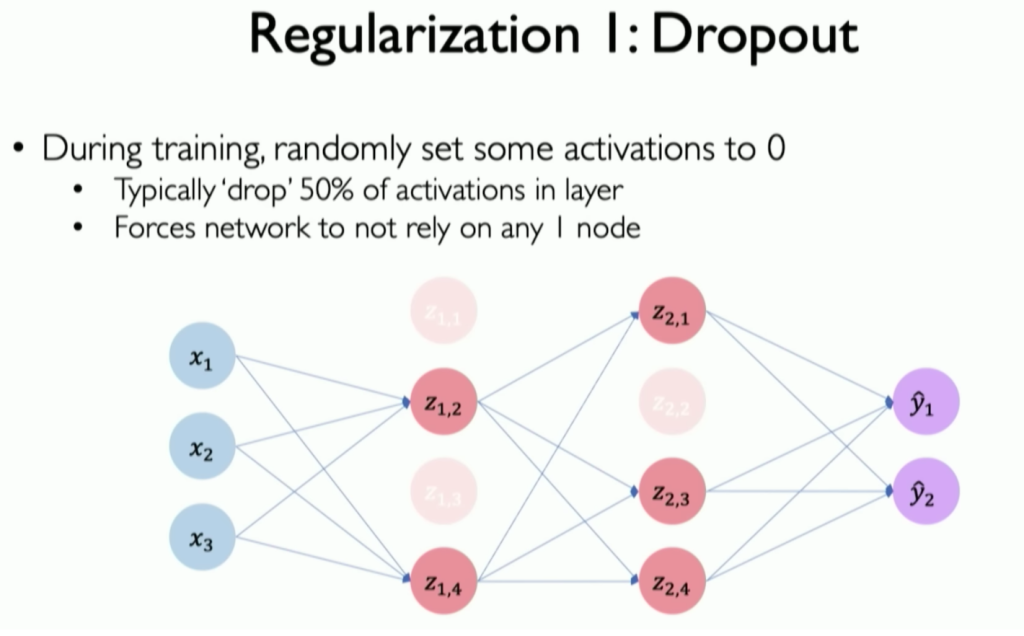
1. Dropout¶
Dropout refers to randomly turning off a fraction of neurons during each training iteration, which helps prevent any single neuron from becoming overly specialized. Basically, each node within the hidden layers has a probability of being turned o, so if the network is trained over multiple iterations of the data, the data is fed through different but simpler networks that result in lower variance than if the same, more complex model was used in each pass. Thus, dropout essentially achieves the same reduction in variance as creating an ensemble of complex networks.
class SimpleNetSequentialDropout(nn.Module):
def __init__(self):
super().__init__()
self.network = nn.Sequential(
nn.Flatten(), # Flatten 28x28 -> 784
nn.Linear(784, 32), # Hidden Layer
nn.ReLU(), # Activation
nn.Dropout(p=0.2),
nn.Linear(32, 10) # Output Layer
)
def forward(self, x):
return self.network(x)
# Initialize Model
model = SimpleNetSequentialDropout().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 200
# Lists to store metrics for plotting
train_losses = []
val_losses = []
print("Starting Training...")
for epoch in range(num_epochs):
# --- TRAINING PHASE ---
model.train() # Turn Dropout ON
running_train_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_train_loss += loss.item()
# Calculate average training loss for this epoch
avg_train_loss = running_train_loss / len(train_loader)
train_losses.append(avg_train_loss)
# --- VALIDATION PHASE ---
model.eval() # Turn Dropout OFF
running_val_loss = 0.0
with torch.no_grad(): # No gradients needed for validation
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_val_loss += loss.item()
# Calculate average validation loss for this epoch
avg_val_loss = running_val_loss / len(val_loader)
val_losses.append(avg_val_loss)
print(f"Epoch [{epoch+1}/{num_epochs}] | Train Loss: {avg_train_loss:.4f} | Val Loss: {avg_val_loss:.4f}")
print("Training Finished!")
Starting Training...
Epoch [1/200] | Train Loss: 1.4367 | Val Loss: 0.7778
Epoch [2/200] | Train Loss: 0.7516 | Val Loss: 0.4850
Epoch [3/200] | Train Loss: 0.5757 | Val Loss: 0.3920
Epoch [4/200] | Train Loss: 0.5006 | Val Loss: 0.3496
Epoch [5/200] | Train Loss: 0.4611 | Val Loss: 0.3210
Epoch [6/200] | Train Loss: 0.4338 | Val Loss: 0.3013
Epoch [7/200] | Train Loss: 0.4126 | Val Loss: 0.2852
Epoch [8/200] | Train Loss: 0.3968 | Val Loss: 0.2745
Epoch [9/200] | Train Loss: 0.3830 | Val Loss: 0.2646
Epoch [10/200] | Train Loss: 0.3708 | Val Loss: 0.2540
Epoch [11/200] | Train Loss: 0.3617 | Val Loss: 0.2494
Epoch [12/200] | Train Loss: 0.3534 | Val Loss: 0.2426
Epoch [13/200] | Train Loss: 0.3418 | Val Loss: 0.2349
Epoch [14/200] | Train Loss: 0.3364 | Val Loss: 0.2296
Epoch [15/200] | Train Loss: 0.3342 | Val Loss: 0.2260
Epoch [16/200] | Train Loss: 0.3238 | Val Loss: 0.2213
Epoch [17/200] | Train Loss: 0.3180 | Val Loss: 0.2179
Epoch [18/200] | Train Loss: 0.3121 | Val Loss: 0.2140
Epoch [19/200] | Train Loss: 0.3062 | Val Loss: 0.2103
Epoch [20/200] | Train Loss: 0.3063 | Val Loss: 0.2088
Epoch [21/200] | Train Loss: 0.3008 | Val Loss: 0.2028
Epoch [22/200] | Train Loss: 0.3012 | Val Loss: 0.2030
Epoch [23/200] | Train Loss: 0.2948 | Val Loss: 0.1987
Epoch [24/200] | Train Loss: 0.2887 | Val Loss: 0.1965
Epoch [25/200] | Train Loss: 0.2854 | Val Loss: 0.1952
Epoch [26/200] | Train Loss: 0.2856 | Val Loss: 0.1928
Epoch [27/200] | Train Loss: 0.2804 | Val Loss: 0.1967
Epoch [28/200] | Train Loss: 0.2757 | Val Loss: 0.1885
Epoch [29/200] | Train Loss: 0.2753 | Val Loss: 0.1869
Epoch [30/200] | Train Loss: 0.2702 | Val Loss: 0.1866
Epoch [31/200] | Train Loss: 0.2694 | Val Loss: 0.1811
Epoch [32/200] | Train Loss: 0.2662 | Val Loss: 0.1853
Epoch [33/200] | Train Loss: 0.2661 | Val Loss: 0.1840
Epoch [34/200] | Train Loss: 0.2644 | Val Loss: 0.1790
Epoch [35/200] | Train Loss: 0.2643 | Val Loss: 0.1771
Epoch [36/200] | Train Loss: 0.2602 | Val Loss: 0.1766
Epoch [37/200] | Train Loss: 0.2563 | Val Loss: 0.1753
Epoch [38/200] | Train Loss: 0.2542 | Val Loss: 0.1736
Epoch [39/200] | Train Loss: 0.2536 | Val Loss: 0.1731
Epoch [40/200] | Train Loss: 0.2499 | Val Loss: 0.1706
Epoch [41/200] | Train Loss: 0.2497 | Val Loss: 0.1715
Epoch [42/200] | Train Loss: 0.2476 | Val Loss: 0.1695
Epoch [43/200] | Train Loss: 0.2473 | Val Loss: 0.1693
Epoch [44/200] | Train Loss: 0.2457 | Val Loss: 0.1724
Epoch [45/200] | Train Loss: 0.2413 | Val Loss: 0.1665
Epoch [46/200] | Train Loss: 0.2422 | Val Loss: 0.1667
Epoch [47/200] | Train Loss: 0.2414 | Val Loss: 0.1702
Epoch [48/200] | Train Loss: 0.2379 | Val Loss: 0.1679
Epoch [49/200] | Train Loss: 0.2356 | Val Loss: 0.1629
Epoch [50/200] | Train Loss: 0.2359 | Val Loss: 0.1633
Epoch [51/200] | Train Loss: 0.2357 | Val Loss: 0.1632
Epoch [52/200] | Train Loss: 0.2330 | Val Loss: 0.1610
Epoch [53/200] | Train Loss: 0.2299 | Val Loss: 0.1630
Epoch [54/200] | Train Loss: 0.2300 | Val Loss: 0.1605
Epoch [55/200] | Train Loss: 0.2327 | Val Loss: 0.1627
Epoch [56/200] | Train Loss: 0.2296 | Val Loss: 0.1605
Epoch [57/200] | Train Loss: 0.2272 | Val Loss: 0.1608
Epoch [58/200] | Train Loss: 0.2275 | Val Loss: 0.1576
Epoch [59/200] | Train Loss: 0.2256 | Val Loss: 0.1611
Epoch [60/200] | Train Loss: 0.2241 | Val Loss: 0.1586
Epoch [61/200] | Train Loss: 0.2232 | Val Loss: 0.1561
Epoch [62/200] | Train Loss: 0.2221 | Val Loss: 0.1572
Epoch [63/200] | Train Loss: 0.2212 | Val Loss: 0.1549
Epoch [64/200] | Train Loss: 0.2195 | Val Loss: 0.1568
Epoch [65/200] | Train Loss: 0.2204 | Val Loss: 0.1551
Epoch [66/200] | Train Loss: 0.2189 | Val Loss: 0.1554
Epoch [67/200] | Train Loss: 0.2179 | Val Loss: 0.1554
Epoch [68/200] | Train Loss: 0.2161 | Val Loss: 0.1566
Epoch [69/200] | Train Loss: 0.2173 | Val Loss: 0.1539
Epoch [70/200] | Train Loss: 0.2160 | Val Loss: 0.1537
Epoch [71/200] | Train Loss: 0.2149 | Val Loss: 0.1530
Epoch [72/200] | Train Loss: 0.2119 | Val Loss: 0.1558
Epoch [73/200] | Train Loss: 0.2118 | Val Loss: 0.1501
Epoch [74/200] | Train Loss: 0.2123 | Val Loss: 0.1511
Epoch [75/200] | Train Loss: 0.2111 | Val Loss: 0.1538
Epoch [76/200] | Train Loss: 0.2092 | Val Loss: 0.1535
Epoch [77/200] | Train Loss: 0.2098 | Val Loss: 0.1517
Epoch [78/200] | Train Loss: 0.2126 | Val Loss: 0.1506
Epoch [79/200] | Train Loss: 0.2122 | Val Loss: 0.1519
Epoch [80/200] | Train Loss: 0.2085 | Val Loss: 0.1547
Epoch [81/200] | Train Loss: 0.2081 | Val Loss: 0.1517
Epoch [82/200] | Train Loss: 0.2093 | Val Loss: 0.1520
Epoch [83/200] | Train Loss: 0.2067 | Val Loss: 0.1528
Epoch [84/200] | Train Loss: 0.2068 | Val Loss: 0.1518
Epoch [85/200] | Train Loss: 0.2059 | Val Loss: 0.1479
Epoch [86/200] | Train Loss: 0.2032 | Val Loss: 0.1495
Epoch [87/200] | Train Loss: 0.2002 | Val Loss: 0.1513
Epoch [88/200] | Train Loss: 0.2031 | Val Loss: 0.1512
Epoch [89/200] | Train Loss: 0.2039 | Val Loss: 0.1511
Epoch [90/200] | Train Loss: 0.2027 | Val Loss: 0.1482
Epoch [91/200] | Train Loss: 0.2017 | Val Loss: 0.1513
Epoch [92/200] | Train Loss: 0.2025 | Val Loss: 0.1507
Epoch [93/200] | Train Loss: 0.1990 | Val Loss: 0.1508
Epoch [94/200] | Train Loss: 0.2016 | Val Loss: 0.1487
Epoch [95/200] | Train Loss: 0.1985 | Val Loss: 0.1526
Epoch [96/200] | Train Loss: 0.2011 | Val Loss: 0.1537
Epoch [97/200] | Train Loss: 0.2000 | Val Loss: 0.1492
Epoch [98/200] | Train Loss: 0.2014 | Val Loss: 0.1514
Epoch [99/200] | Train Loss: 0.1958 | Val Loss: 0.1487
Epoch [100/200] | Train Loss: 0.1961 | Val Loss: 0.1477
Epoch [101/200] | Train Loss: 0.1989 | Val Loss: 0.1490
Epoch [102/200] | Train Loss: 0.1931 | Val Loss: 0.1496
Epoch [103/200] | Train Loss: 0.1934 | Val Loss: 0.1499
Epoch [104/200] | Train Loss: 0.1938 | Val Loss: 0.1472
Epoch [105/200] | Train Loss: 0.1947 | Val Loss: 0.1478
Epoch [106/200] | Train Loss: 0.1986 | Val Loss: 0.1507
Epoch [107/200] | Train Loss: 0.1951 | Val Loss: 0.1492
Epoch [108/200] | Train Loss: 0.1980 | Val Loss: 0.1509
Epoch [109/200] | Train Loss: 0.1993 | Val Loss: 0.1478
Epoch [110/200] | Train Loss: 0.1956 | Val Loss: 0.1514
Epoch [111/200] | Train Loss: 0.1935 | Val Loss: 0.1512
Epoch [112/200] | Train Loss: 0.1912 | Val Loss: 0.1531
Epoch [113/200] | Train Loss: 0.1928 | Val Loss: 0.1484
Epoch [114/200] | Train Loss: 0.1900 | Val Loss: 0.1516
Epoch [115/200] | Train Loss: 0.1922 | Val Loss: 0.1520
Epoch [116/200] | Train Loss: 0.1937 | Val Loss: 0.1486
Epoch [117/200] | Train Loss: 0.1900 | Val Loss: 0.1525
Epoch [118/200] | Train Loss: 0.1895 | Val Loss: 0.1480
Epoch [119/200] | Train Loss: 0.1889 | Val Loss: 0.1489
Epoch [120/200] | Train Loss: 0.1910 | Val Loss: 0.1488
Epoch [121/200] | Train Loss: 0.1906 | Val Loss: 0.1510
Epoch [122/200] | Train Loss: 0.1897 | Val Loss: 0.1491
Epoch [123/200] | Train Loss: 0.1881 | Val Loss: 0.1532
Epoch [124/200] | Train Loss: 0.1887 | Val Loss: 0.1505
Epoch [125/200] | Train Loss: 0.1906 | Val Loss: 0.1517
Epoch [126/200] | Train Loss: 0.1877 | Val Loss: 0.1495
Epoch [127/200] | Train Loss: 0.1871 | Val Loss: 0.1482
Epoch [128/200] | Train Loss: 0.1863 | Val Loss: 0.1460
Epoch [129/200] | Train Loss: 0.1875 | Val Loss: 0.1463
Epoch [130/200] | Train Loss: 0.1822 | Val Loss: 0.1511
Epoch [131/200] | Train Loss: 0.1877 | Val Loss: 0.1472
Epoch [132/200] | Train Loss: 0.1823 | Val Loss: 0.1492
Epoch [133/200] | Train Loss: 0.1818 | Val Loss: 0.1487
Epoch [134/200] | Train Loss: 0.1815 | Val Loss: 0.1537
Epoch [135/200] | Train Loss: 0.1864 | Val Loss: 0.1501
Epoch [136/200] | Train Loss: 0.1820 | Val Loss: 0.1482
Epoch [137/200] | Train Loss: 0.1793 | Val Loss: 0.1508
Epoch [138/200] | Train Loss: 0.1842 | Val Loss: 0.1519
Epoch [139/200] | Train Loss: 0.1863 | Val Loss: 0.1487
Epoch [140/200] | Train Loss: 0.1884 | Val Loss: 0.1487
Epoch [141/200] | Train Loss: 0.1850 | Val Loss: 0.1509
Epoch [142/200] | Train Loss: 0.1839 | Val Loss: 0.1512
Epoch [143/200] | Train Loss: 0.1828 | Val Loss: 0.1486
Epoch [144/200] | Train Loss: 0.1820 | Val Loss: 0.1526
Epoch [145/200] | Train Loss: 0.1836 | Val Loss: 0.1514
Epoch [146/200] | Train Loss: 0.1808 | Val Loss: 0.1547
Epoch [147/200] | Train Loss: 0.1832 | Val Loss: 0.1496
Epoch [148/200] | Train Loss: 0.1795 | Val Loss: 0.1484
Epoch [149/200] | Train Loss: 0.1842 | Val Loss: 0.1485
Epoch [150/200] | Train Loss: 0.1806 | Val Loss: 0.1487
Epoch [151/200] | Train Loss: 0.1808 | Val Loss: 0.1491
Epoch [152/200] | Train Loss: 0.1821 | Val Loss: 0.1476
Epoch [153/200] | Train Loss: 0.1776 | Val Loss: 0.1521
Epoch [154/200] | Train Loss: 0.1791 | Val Loss: 0.1544
Epoch [155/200] | Train Loss: 0.1784 | Val Loss: 0.1500
Epoch [156/200] | Train Loss: 0.1779 | Val Loss: 0.1488
Epoch [157/200] | Train Loss: 0.1799 | Val Loss: 0.1504
Epoch [158/200] | Train Loss: 0.1813 | Val Loss: 0.1515
Epoch [159/200] | Train Loss: 0.1785 | Val Loss: 0.1526
Epoch [160/200] | Train Loss: 0.1784 | Val Loss: 0.1559
Epoch [161/200] | Train Loss: 0.1789 | Val Loss: 0.1553
Epoch [162/200] | Train Loss: 0.1771 | Val Loss: 0.1490
Epoch [163/200] | Train Loss: 0.1818 | Val Loss: 0.1514
Epoch [164/200] | Train Loss: 0.1835 | Val Loss: 0.1522
Epoch [165/200] | Train Loss: 0.1784 | Val Loss: 0.1493
Epoch [166/200] | Train Loss: 0.1790 | Val Loss: 0.1495
Epoch [167/200] | Train Loss: 0.1753 | Val Loss: 0.1546
Epoch [168/200] | Train Loss: 0.1765 | Val Loss: 0.1485
Epoch [169/200] | Train Loss: 0.1761 | Val Loss: 0.1523
Epoch [170/200] | Train Loss: 0.1762 | Val Loss: 0.1517
Epoch [171/200] | Train Loss: 0.1773 | Val Loss: 0.1562
Epoch [172/200] | Train Loss: 0.1797 | Val Loss: 0.1507
Epoch [173/200] | Train Loss: 0.1754 | Val Loss: 0.1523
Epoch [174/200] | Train Loss: 0.1778 | Val Loss: 0.1512
Epoch [175/200] | Train Loss: 0.1772 | Val Loss: 0.1524
Epoch [176/200] | Train Loss: 0.1737 | Val Loss: 0.1513
Epoch [177/200] | Train Loss: 0.1738 | Val Loss: 0.1539
Epoch [178/200] | Train Loss: 0.1747 | Val Loss: 0.1493
Epoch [179/200] | Train Loss: 0.1746 | Val Loss: 0.1508
Epoch [180/200] | Train Loss: 0.1788 | Val Loss: 0.1477
Epoch [181/200] | Train Loss: 0.1748 | Val Loss: 0.1523
Epoch [182/200] | Train Loss: 0.1706 | Val Loss: 0.1608
Epoch [183/200] | Train Loss: 0.1729 | Val Loss: 0.1510
Epoch [184/200] | Train Loss: 0.1772 | Val Loss: 0.1591
Epoch [185/200] | Train Loss: 0.1778 | Val Loss: 0.1518
Epoch [186/200] | Train Loss: 0.1730 | Val Loss: 0.1560
Epoch [187/200] | Train Loss: 0.1688 | Val Loss: 0.1510
Epoch [188/200] | Train Loss: 0.1716 | Val Loss: 0.1499
Epoch [189/200] | Train Loss: 0.1726 | Val Loss: 0.1531
Epoch [190/200] | Train Loss: 0.1748 | Val Loss: 0.1528
Epoch [191/200] | Train Loss: 0.1742 | Val Loss: 0.1541
Epoch [192/200] | Train Loss: 0.1725 | Val Loss: 0.1514
Epoch [193/200] | Train Loss: 0.1735 | Val Loss: 0.1533
Epoch [194/200] | Train Loss: 0.1759 | Val Loss: 0.1505
Epoch [195/200] | Train Loss: 0.1718 | Val Loss: 0.1587
Epoch [196/200] | Train Loss: 0.1700 | Val Loss: 0.1551
Epoch [197/200] | Train Loss: 0.1702 | Val Loss: 0.1555
Epoch [198/200] | Train Loss: 0.1711 | Val Loss: 0.1522
Epoch [199/200] | Train Loss: 0.1695 | Val Loss: 0.1560
Epoch [200/200] | Train Loss: 0.1671 | Val Loss: 0.1540
Training Finished!
import plotly.express as px
import pandas as pd
# Prepare data
epochs = list(range(1, len(train_losses) + 1))
df = pd.DataFrame({
"Epoch": epochs * 2,
"Loss": train_losses + val_losses,
"Type": ["Training"] * len(train_losses) + ["Validation"] * len(val_losses)
})
# Create line plot
fig = px.line(df, x="Epoch", y="Loss", color="Type", title="Training vs. Validation Loss")
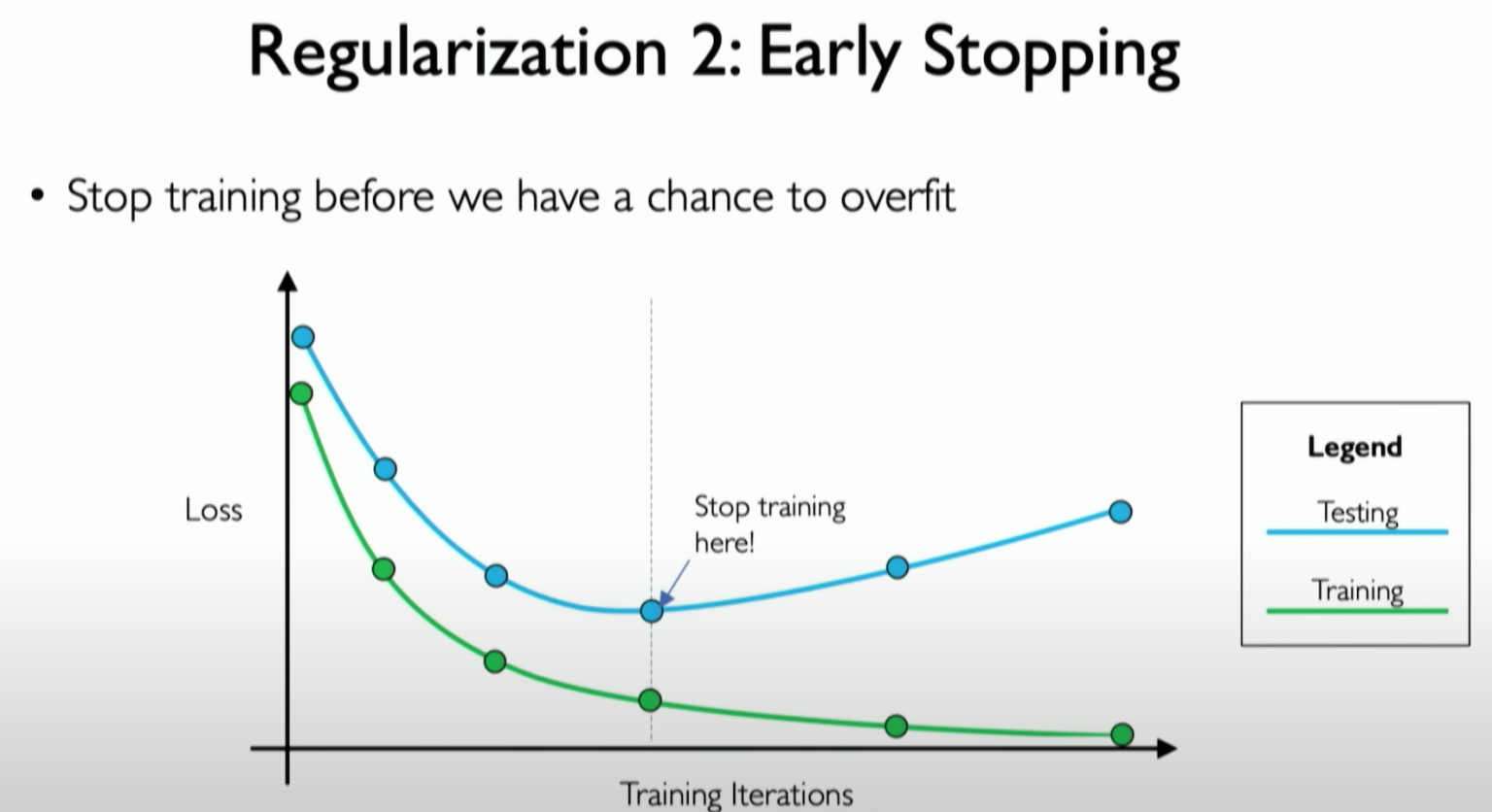
fig.show()2. Early Stopping¶
Stops training when validation loss stops improving.
Early stopping essentially terminates the training of a deep learning model if after a certain number of iterations, the magnitude of decrease in the loss function is within a small threshold. Using early stopping makes it possible to set the number of iterations to a large number, as assuming the loss function will eventually bottom out before the final iteration, the model is not trained all the way out. This can be very beneficial in conserving computing resources.
# Pseudocode for early stopping
best_val_loss = float('inf')
patience = 5
counter = 0
for epoch in range(num_epochs):
# ... training loop ...
if val_loss < best_val_loss:
best_val_loss = val_loss
counter = 0
else:
counter += 1
if counter >= patience:
print("Early stopping triggered!")
breakprint(model)SimpleNetSequential(
(network): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=32, bias=True)
(2): ReLU()
(3): Linear(in_features=32, out_features=10, bias=True)
)
)
num_epochs = 200
# Early stopping parameters
patience = 5
best_val_loss = float('inf')
counter = 0
# Lists to store metrics for plotting
train_losses = []
val_losses = []
print("Starting Training...")
for epoch in range(num_epochs):
# --- TRAINING PHASE ---
model.train() # Turn Dropout ON
running_train_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_train_loss += loss.item()
# Calculate average training loss for this epoch
avg_train_loss = running_train_loss / len(train_loader)
train_losses.append(avg_train_loss)
# --- VALIDATION PHASE ---
model.eval() # Turn Dropout OFF
running_val_loss = 0.0
with torch.no_grad(): # No gradients needed for validation
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_val_loss += loss.item()
# Calculate average validation loss for this epoch
avg_val_loss = running_val_loss / len(val_loader)
val_losses.append(avg_val_loss)
print(f"Epoch [{epoch+1}/{num_epochs}] | Train Loss: {avg_train_loss:.4f} | Val Loss: {avg_val_loss:.4f}")
# --- EARLY STOPPING CHECK ---
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
counter = 0
else:
counter += 1
if counter >= patience:
print(f"Early stopping triggered at epoch {epoch+1}!")
break
print("Training Finished!")Starting Training...
Epoch [1/200] | Train Loss: 1.5602 | Val Loss: 0.9350
Epoch [2/200] | Train Loss: 0.7085 | Val Loss: 0.5584
Epoch [3/200] | Train Loss: 0.4929 | Val Loss: 0.4392
Epoch [4/200] | Train Loss: 0.4113 | Val Loss: 0.3821
Epoch [5/200] | Train Loss: 0.3715 | Val Loss: 0.3495
Epoch [6/200] | Train Loss: 0.3480 | Val Loss: 0.3336
Epoch [7/200] | Train Loss: 0.3302 | Val Loss: 0.3203
Epoch [8/200] | Train Loss: 0.3189 | Val Loss: 0.3089
Epoch [9/200] | Train Loss: 0.3087 | Val Loss: 0.3010
Epoch [10/200] | Train Loss: 0.3014 | Val Loss: 0.2969
Epoch [11/200] | Train Loss: 0.2953 | Val Loss: 0.2910
Epoch [12/200] | Train Loss: 0.2888 | Val Loss: 0.2865
Epoch [13/200] | Train Loss: 0.2842 | Val Loss: 0.2793
Epoch [14/200] | Train Loss: 0.2794 | Val Loss: 0.2768
Epoch [15/200] | Train Loss: 0.2755 | Val Loss: 0.2746
Epoch [16/200] | Train Loss: 0.2708 | Val Loss: 0.2713
Epoch [17/200] | Train Loss: 0.2665 | Val Loss: 0.2668
Epoch [18/200] | Train Loss: 0.2622 | Val Loss: 0.2681
Epoch [19/200] | Train Loss: 0.2598 | Val Loss: 0.2662
Epoch [20/200] | Train Loss: 0.2560 | Val Loss: 0.2603
Epoch [21/200] | Train Loss: 0.2516 | Val Loss: 0.2563
Epoch [22/200] | Train Loss: 0.2499 | Val Loss: 0.2605
Epoch [23/200] | Train Loss: 0.2464 | Val Loss: 0.2510
Epoch [24/200] | Train Loss: 0.2433 | Val Loss: 0.2491
Epoch [25/200] | Train Loss: 0.2393 | Val Loss: 0.2467
Epoch [26/200] | Train Loss: 0.2361 | Val Loss: 0.2464
Epoch [27/200] | Train Loss: 0.2333 | Val Loss: 0.2452
Epoch [28/200] | Train Loss: 0.2321 | Val Loss: 0.2422
Epoch [29/200] | Train Loss: 0.2285 | Val Loss: 0.2384
Epoch [30/200] | Train Loss: 0.2259 | Val Loss: 0.2350
Epoch [31/200] | Train Loss: 0.2228 | Val Loss: 0.2319
Epoch [32/200] | Train Loss: 0.2198 | Val Loss: 0.2338
Epoch [33/200] | Train Loss: 0.2177 | Val Loss: 0.2269
Epoch [34/200] | Train Loss: 0.2137 | Val Loss: 0.2250
Epoch [35/200] | Train Loss: 0.2127 | Val Loss: 0.2262
Epoch [36/200] | Train Loss: 0.2107 | Val Loss: 0.2246
Epoch [37/200] | Train Loss: 0.2079 | Val Loss: 0.2231
Epoch [38/200] | Train Loss: 0.2044 | Val Loss: 0.2170
Epoch [39/200] | Train Loss: 0.2028 | Val Loss: 0.2174
Epoch [40/200] | Train Loss: 0.2015 | Val Loss: 0.2215
Epoch [41/200] | Train Loss: 0.1988 | Val Loss: 0.2130
Epoch [42/200] | Train Loss: 0.1968 | Val Loss: 0.2162
Epoch [43/200] | Train Loss: 0.1956 | Val Loss: 0.2101
Epoch [44/200] | Train Loss: 0.1934 | Val Loss: 0.2077
Epoch [45/200] | Train Loss: 0.1924 | Val Loss: 0.2078
Epoch [46/200] | Train Loss: 0.1899 | Val Loss: 0.2091
Epoch [47/200] | Train Loss: 0.1891 | Val Loss: 0.2076
Epoch [48/200] | Train Loss: 0.1875 | Val Loss: 0.2044
Epoch [49/200] | Train Loss: 0.1858 | Val Loss: 0.2028
Epoch [50/200] | Train Loss: 0.1838 | Val Loss: 0.2012
Epoch [51/200] | Train Loss: 0.1817 | Val Loss: 0.2010
Epoch [52/200] | Train Loss: 0.1808 | Val Loss: 0.2003
Epoch [53/200] | Train Loss: 0.1802 | Val Loss: 0.1974
Epoch [54/200] | Train Loss: 0.1790 | Val Loss: 0.1987
Epoch [55/200] | Train Loss: 0.1769 | Val Loss: 0.1963
Epoch [56/200] | Train Loss: 0.1772 | Val Loss: 0.2020
Epoch [57/200] | Train Loss: 0.1748 | Val Loss: 0.1975
Epoch [58/200] | Train Loss: 0.1736 | Val Loss: 0.1977
Epoch [59/200] | Train Loss: 0.1718 | Val Loss: 0.1941
Epoch [60/200] | Train Loss: 0.1709 | Val Loss: 0.1933
Epoch [61/200] | Train Loss: 0.1710 | Val Loss: 0.1932
Epoch [62/200] | Train Loss: 0.1681 | Val Loss: 0.1918
Epoch [63/200] | Train Loss: 0.1693 | Val Loss: 0.1908
Epoch [64/200] | Train Loss: 0.1677 | Val Loss: 0.1918
Epoch [65/200] | Train Loss: 0.1660 | Val Loss: 0.1905
Epoch [66/200] | Train Loss: 0.1650 | Val Loss: 0.1874
Epoch [67/200] | Train Loss: 0.1638 | Val Loss: 0.1888
Epoch [68/200] | Train Loss: 0.1629 | Val Loss: 0.1882
Epoch [69/200] | Train Loss: 0.1611 | Val Loss: 0.1886
Epoch [70/200] | Train Loss: 0.1617 | Val Loss: 0.1931
Epoch [71/200] | Train Loss: 0.1599 | Val Loss: 0.1870
Epoch [72/200] | Train Loss: 0.1584 | Val Loss: 0.1869
Epoch [73/200] | Train Loss: 0.1591 | Val Loss: 0.1850
Epoch [74/200] | Train Loss: 0.1576 | Val Loss: 0.1878
Epoch [75/200] | Train Loss: 0.1559 | Val Loss: 0.1855
Epoch [76/200] | Train Loss: 0.1557 | Val Loss: 0.1860
Epoch [77/200] | Train Loss: 0.1551 | Val Loss: 0.1838
Epoch [78/200] | Train Loss: 0.1538 | Val Loss: 0.1853
Epoch [79/200] | Train Loss: 0.1530 | Val Loss: 0.1839
Epoch [80/200] | Train Loss: 0.1527 | Val Loss: 0.1818
Epoch [81/200] | Train Loss: 0.1521 | Val Loss: 0.1825
Epoch [82/200] | Train Loss: 0.1526 | Val Loss: 0.1831
Epoch [83/200] | Train Loss: 0.1496 | Val Loss: 0.1851
Epoch [84/200] | Train Loss: 0.1480 | Val Loss: 0.1806
Epoch [85/200] | Train Loss: 0.1480 | Val Loss: 0.1827
Epoch [86/200] | Train Loss: 0.1477 | Val Loss: 0.1811
Epoch [87/200] | Train Loss: 0.1460 | Val Loss: 0.1783
Epoch [88/200] | Train Loss: 0.1457 | Val Loss: 0.1819
Epoch [89/200] | Train Loss: 0.1460 | Val Loss: 0.1827
Epoch [90/200] | Train Loss: 0.1442 | Val Loss: 0.1786
Epoch [91/200] | Train Loss: 0.1441 | Val Loss: 0.1823
Epoch [92/200] | Train Loss: 0.1433 | Val Loss: 0.1796
Early stopping triggered at epoch 92!
Training Finished!
import plotly.express as px
import pandas as pd
# Prepare data
epochs = list(range(1, len(train_losses) + 1))
df = pd.DataFrame({
"Epoch": epochs * 2,
"Loss": train_losses + val_losses,
"Type": ["Training"] * len(train_losses) + ["Validation"] * len(val_losses)
})
# Create line plot
fig = px.line(df, x="Epoch", y="Loss", color="Type", title="Training vs. Validation Loss")
fig.show()3. L2 Regularization (Weight Decay)¶
Penalizes large weights by adding their squared value to the loss.
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)Exercise: Build a “Mixed-Activation” Network¶
The Scenario: You are experimenting with a new architecture that mixes old-school and modern techniques. You need to build a classifier for MNIST that uses two small hidden layers with different activation functions to see how they interact.
The Specifications:
Input: Flatten the standard MNIST images (28 x 28).
Hidden Layer 1:
Size: 16 neurons
Activation: Sigmoid
Regularization: Dropout with probability 0.1
Hidden Layer 2:
Size: 16 neurons
Activation: ReLU
Regularization: Dropout with probability 0.1
Output Layer:
Size: 10 neurons (for the 10 digit classes)
class CustomNet(nn.Module):
def __init__(self):
super().__init__()
self.network = ... # YOUR CODE HERE
def forward(self, x):
return self.network(x)
# Instantiate and print the model
model = CustomNet()
print(model)